L' Ascension spectaculaire des décès subits et inattendus d’Allemands en 2021 résulteraient d’erreurs dans les données. C’étaient certainement des chiffres incroyablement sensationnels et en même temps: si quelque chose est aussi rare que la « mort subite », alors vous verrez bientôt des doublements ou plus si quelque chose bouge dans cette région. De plus, les données provenaient d’un excellent institut gouvernemental et l’analyste impliqué Tom Lausen connaît parfaitement bien la question. Plusieurs examens indépendants ont largement confirmé ses conclusions.
Bien sûr, il y a eu aussi beaucoup de bavardages: diverses vérifications des faits ne vont pas plus loin que le fait que l’analyse de Tom Lausen était incorrecte et que les chiffres n’étaient pas destinés à une telle analyse. Il est également affirmé que les données ont été délibérément demandées d’une manière qui ne pouvait que conduire à ce résultat. En bref: panique chez de nombreux vérificateurs de faits, Exceptions à part ça.
Mais: il semble qu’il se passe quelque chose. Où sommes-nous tombés dans le piège? Sommes-nous vraiment entrés dans quelque chose? Alors voyons par vous-même.
Qu’est-ce qui a été demandé exactement?
Trois ensembles de données ont été demandés. Les deux premiers paquets de données n’ont été assurés qu’en 2021. Cela ne pourrait donc pas inclure les chiffres de mortalité des années précédentes, ce qui expliquerait l’absence de codes de mortalité jusqu’en 2021. Mais le troisième paquet concernait vraiment Tous les assurés de 2016-2021.
Vous serez responsable de l’envoi par trimestres d’une ventilation de la fréquence de tous les codes CIM de toutes les personnes assurées – à l’exclusion des personnes assurées du forfait 1 – pour la période 2016-2021, si disponible également pour 2022. Les données doivent être récupérées avec V et G.
Demande de données de confirmation
Forfait 3. Sie beantragen die Übermittlung einer Auf,istung der Häufigkeit aller ICD-Codes aller Versicherten – ohne die Versichtertenmenge aus Paket 1 – für de Zeitraum 2016 bis 2021, falls anteilig vorliegend auch für 2022, nach Quartalen. Die Datenabfrage soll mit V und G erfolgen.

On prétend maintenant que le paquet 3 a été livré de manière incomplète: les assurés qui étaient déjà décédés avant 2021 n’en faisaient pas partie, il ne contiendrait que les personnes qui étaient encore enregistrées comme assurées en 2021. Ils ne pouvaient donc pas avoir de codes de mortalité en 2016-2020... D’où les différences absurdes avec 2021. Volonté ou malentendu, nous laissons cela au milieu.
Pourtant, ce n’est pas vrai non plus.
Nous supposons un instant que les données concernaient effectivement des personnes qui étaient encore en vie en 2021. Apparemment, le 1er janvier 2021 a été pris comme date de référence. Si le 31 décembre avait été choisi, aucun décès n’aurait été visible, du moins selon ce raisonnement. Après tout, vous pouvez supposer qu’une personne, une fois décédée, n’est plus considérée comme une personne assurée. Le 31 décembre, toutes les personnes décédées cette année-là ont été radiées de la liste des assurés. Ensuite, vous n’avez plus rien à signaler si vous réfléchissez assez franchement.
Si quelqu’un qui a dû recueillir les données s’en est rendu compte, il est au moins frappant de constater qu’il n’a pas emporté 2016-2020 avec lui ou qu’il n’a pas demandé quelle était son intention.
Dans cet esprit, le graphique global montre quelque chose d’étrange:
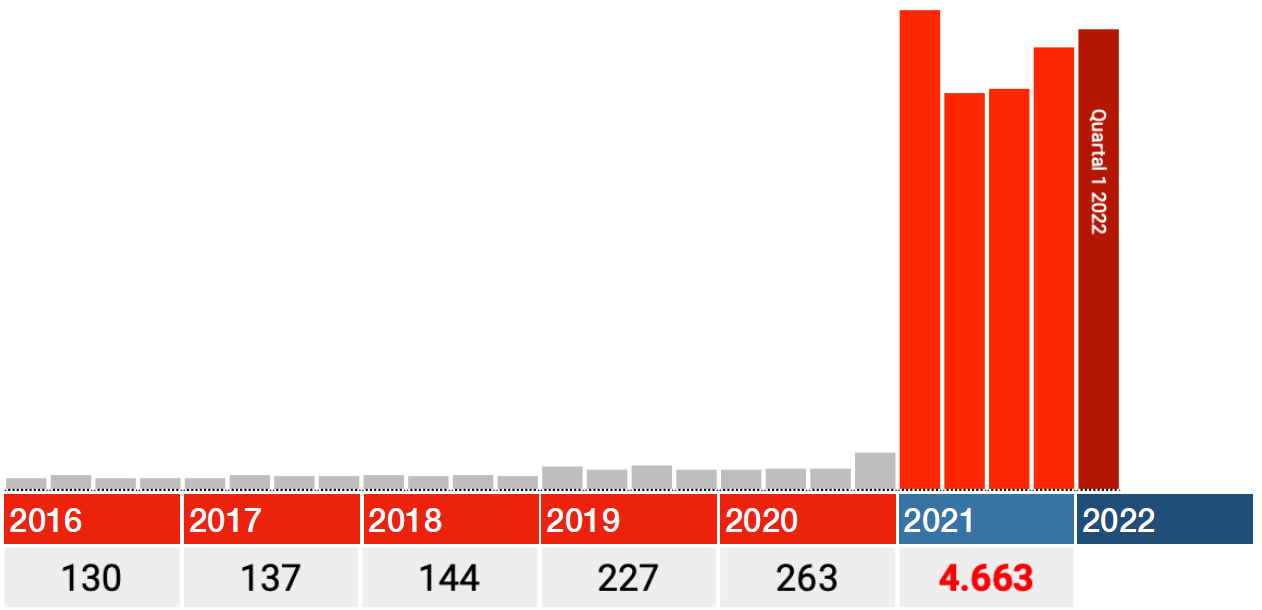
Parmi les personnes encore en vie en 2021, une fois et demie plus sont mortes en 2016-2020 qu’en 2021 même.
Relisez-le.
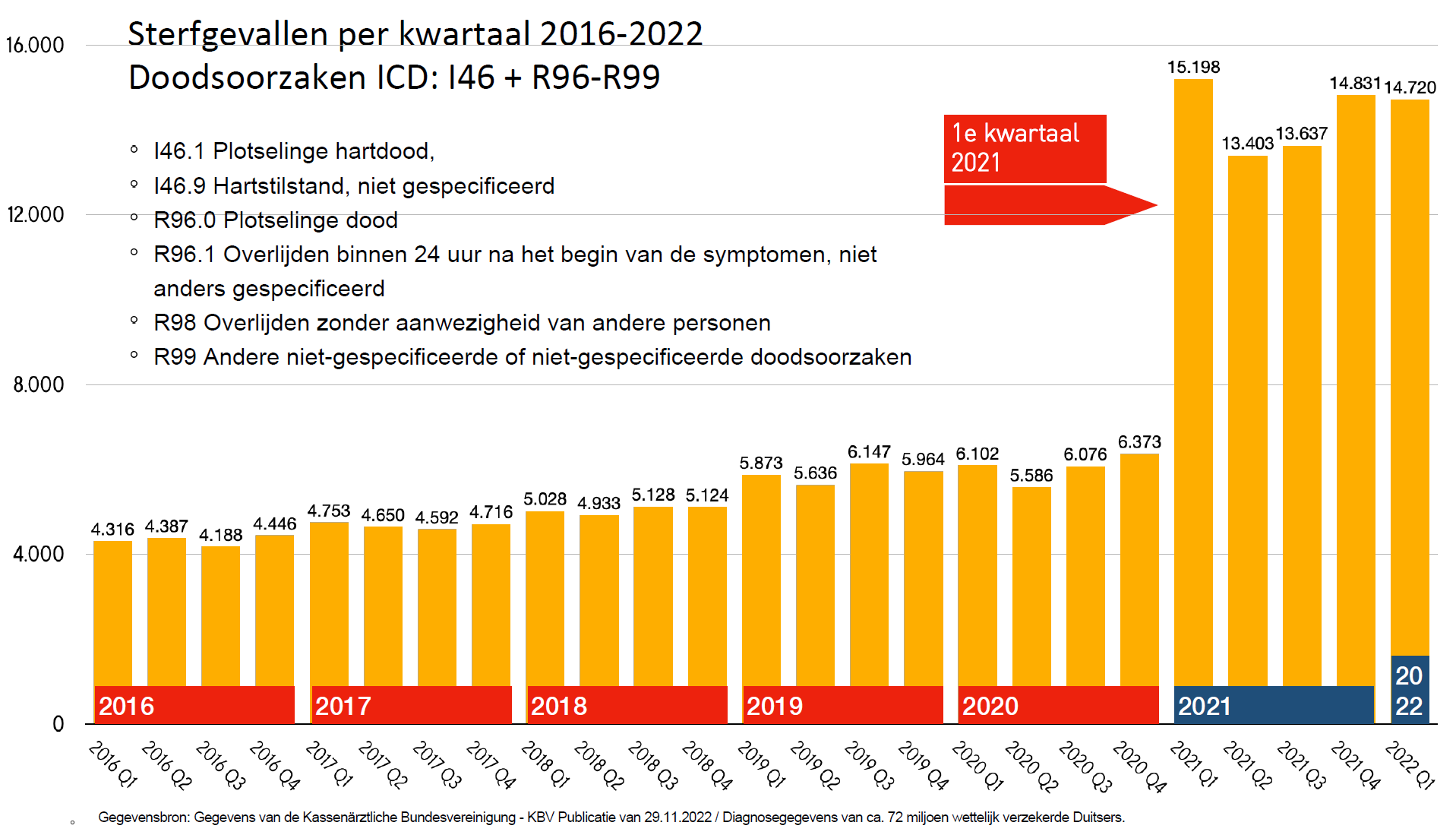
Ceci est commodément expliqué par les experts comme une « erreur de saisie ». Nous comprenons cela; Après tout, les vaccins ne peuvent pas l’être. Mais ensuite, c’est une erreur de saisie qui a été rendue de plus en plus facile, comme en témoigne la tendance à la légère hausse de 2016-2019. Nous pouvons supposer que cette tendance se poursuivra en 2021. Ensuite, environ 40% des données fournies par l’Institut Paul Ehrlich pour 2021 sont tout simplement fausses car il n’y a aucune raison de croire que ces erreurs de saisie ne se sont soudainement plus produites là-bas ...
Et si les données des années antérieures à 2021 décédées ne sont pas du tout incluses, d’où viennent réellement ces « erreurs de saisie »!?
40% d’erreurs de saisie, n’est-ce pas même pour l’industrie médicale?
S’il est mal entré à la source, il n’est pas facile de le savoir. Cette source, ce sont les médecins : il s’agit des réclamations (rapports de coûts) que les médecins envoient aux assureurs. C’est pourquoi nous pensons aussi à la fraude plutôt qu’aux erreurs. Les médecins auraient délibérément abandonné plus d’actions qu’ils n’en ont réellement effectuées. Cela soulève également des questions et des objections:
- Ce ne sont pas des actes, ce sont des circonstances de décès, telles que « décédé sans la présence d’autres personnes »
- Les médecins reçoivent-ils de l’argent supplémentaire si quelqu’un meurt sans la présence d’autres personnes...?
- Si, en tant que médecin, vous voulez augmenter quelque chose, le faites-vous avec la mort subite de vos propres patients (votre clientèle, vous réduisez votre pratique) ou cochez-vous des ongles incarnés supplémentaires, des points de suture ou des infections des oreilles et des yeux? Il existe sans aucun doute des actions moins drastiques, plus courantes, plus chronophages que l’observation d’une mort subite qui ne peut plus être faite.
Est-ce parfois avec les assureurs-maladie ou avec le parapluie fédéral?
Un autre point de pollution peut être les assureurs maladie eux-mêmes. Ils n’ont pas le droit de faire des profits énormes, alors ils pourraient trouver des coûts pour maintenir les primes à niveau. Même dans ce cas, les décès ne semblent pas être le poste de coût approprié, du moins si vous ne voulez pas le faire ressortir.
Revenons à la question : comment cette énorme pollution pénètre-t-elle dans les données ? La faute en est-elle peut-être à l’institut de recherche sur les vaccins et les biomédicaments, l’Institut Paul Ehrluch, qui a recueilli toutes les données? Des erreurs cardinales sont également commises dans les instituts, que nous avons vues à plusieurs reprises dans nos propres instituts.
Il est bon de se rendre compte que la situation en Allemagne est différente de celle des Pays-Bas: un institut « fédéral » collecte les données des Länder de la région. Chaque Land a son propre assureur maladie ou « Kassenärtzlichen Vereinigung » (NRW en a deux). Il y a donc 17 KV, réunis dans une Bundesvereinigung.
Facteur 17
Si l’institut fédéral a demandé à tort des données à tous les instituts sauf un, cela pourrait expliquer ce graphique.
Ensuite, il y a un institut qui a également transmis 2016-2019, c’est de là que vient cette poignée de données. Les seize autres n’ont soumis que 2021.

Indication
Cela pourra-t-il jamais être reconstruit? L’institut a peut-être transmis la question directement et seulement 1 des dix-sept a compris la question telle qu’elle était prévue, le reste uniquement sur pilote automatique (après le forfait 1 et le forfait 2) s’est également avéré le paquet trois pour 2021 seulement.
Lors de la fusion des données, il n’y a encore aucune attention. Un institut gouvernemental responsable des données devrait veiller à ce que les ensembles de données ne soient pas compilés de façon uniforme. Contrôle de l’entrée des gènes? Pas de contrôle de sortie ?
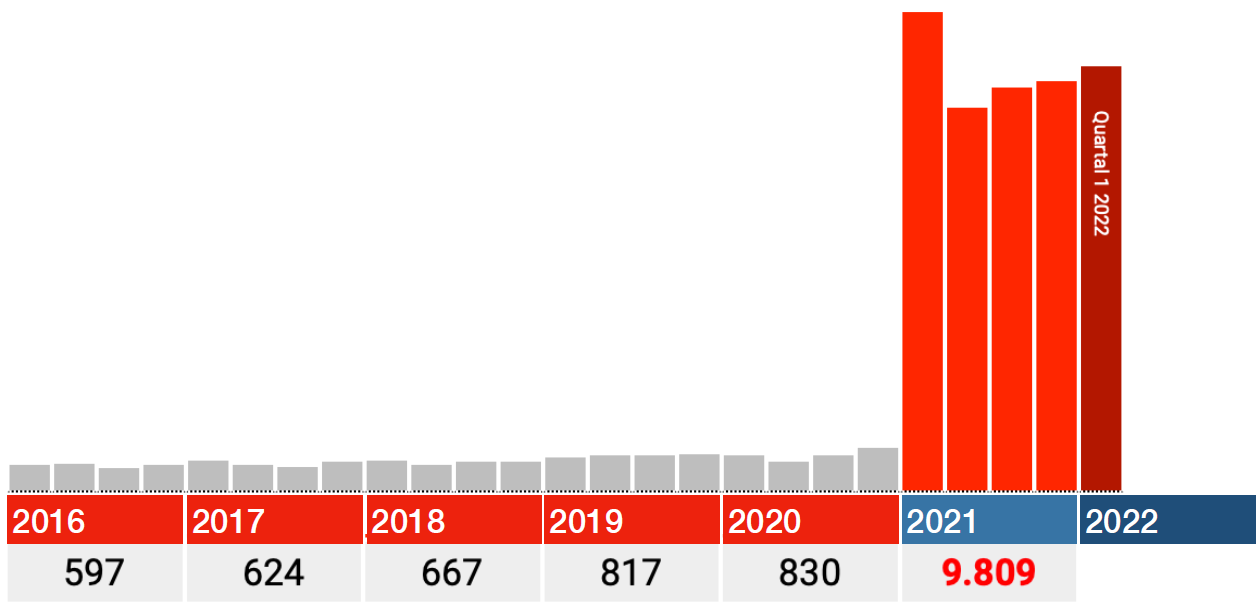
Ce facteur de 17 devrait alors plus ou moins s’appliquer également à d’autres codes. Nous avons vu un facteur de 16,7, ce qui correspond à cela. Pour les autres codes, cela devrait plus ou moins être le cas. Avec une certaine marge, ils devraient être de l’ordre de 15 à 20.
Ce n’est pas le cas. Les facteurs y sont d’environ 10, 6 et 3 (seul le graphique du facteur 3 est montré, 293% pour être exact). En aucun cas un facteur de 17 et les Bundesländer ne seront pas si différents, n’est-ce pas?
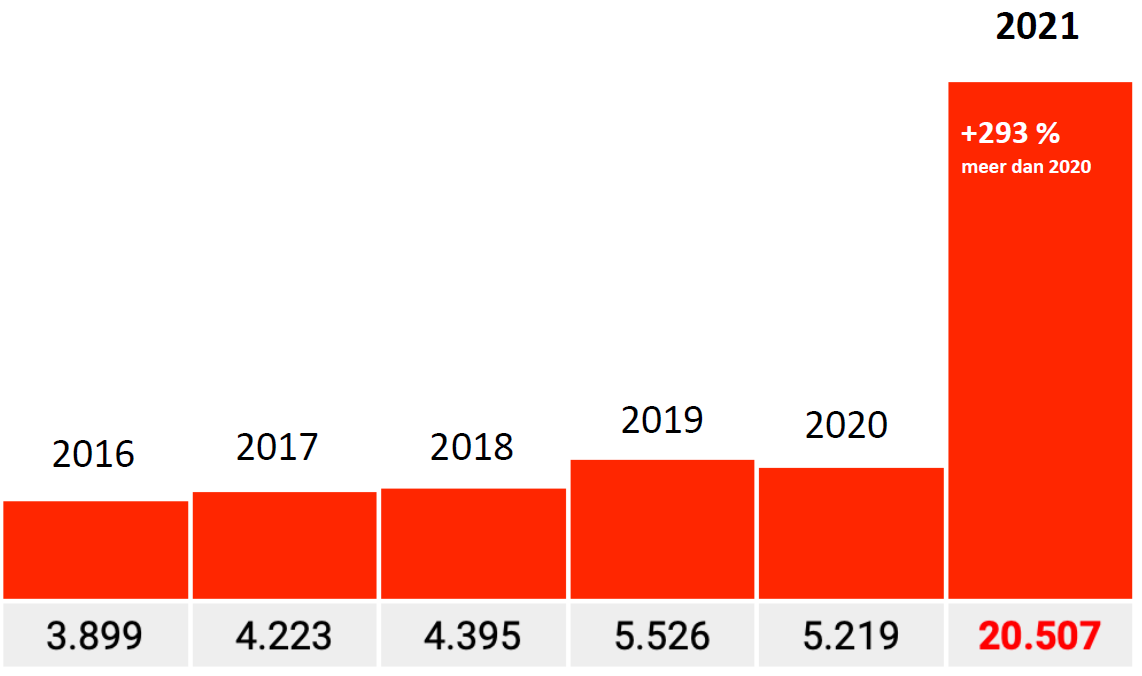
Facteur 0,2
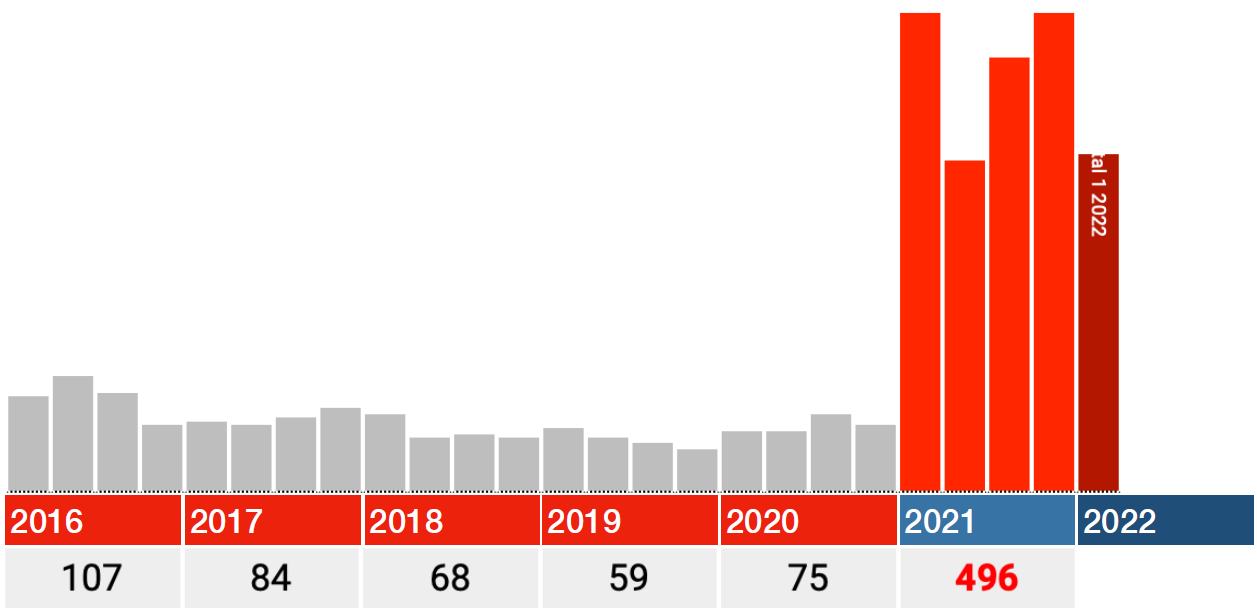
Voilà pour les différences absurdes. Regardons simplement le code I46.1: Décès dû à une insuffisance cardiaque soudaine, alors la différence n’est soudainement que d’environ 20% avec 2020. Quelle erreur système ou « erreur d’entrée » aurait pu être reproduite? L’insuffisance cardiaque soudaine est une cause réelle de décès, les autres codes sont des circonstances, peut-être que cela a été traité différemment? Ce code a également été ajouté ultérieurement.
Serait-ce le seul graphique dans lequel les années 2016-2020 sont correctement incluses? Dans tous les cas, une augmentation de 15 à 20% semble plus crédible qu’une augmentation de 1700%. Le message n’est pas moins urgent: enquêtez là-dessus! (et en attendant, arrêtez cette vaccination sur rien).
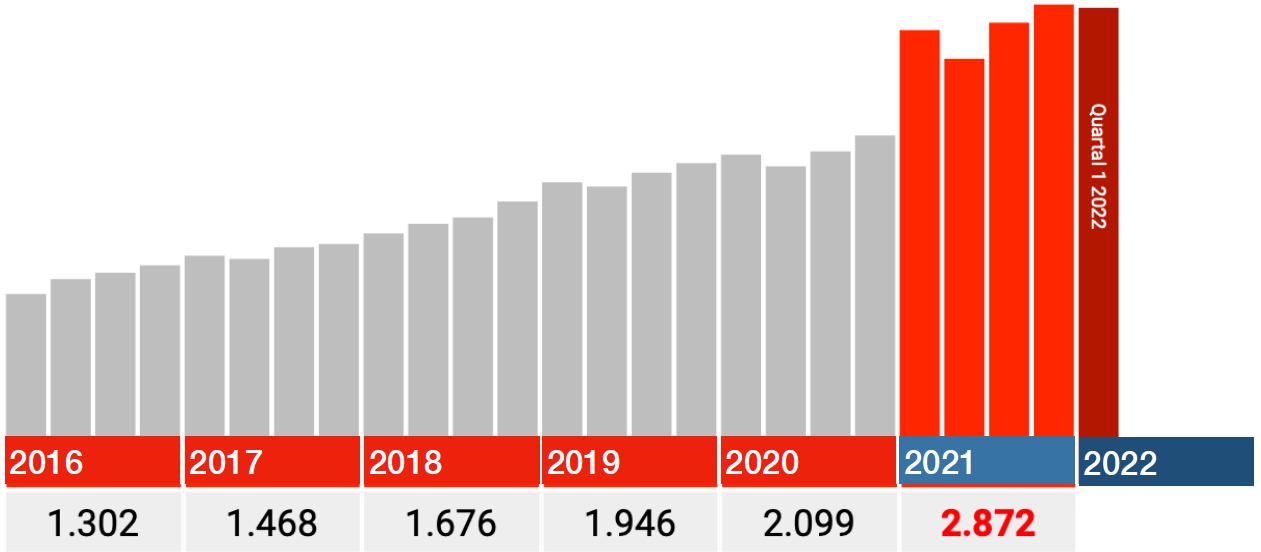
Comment fonctionnent les autres codes I.46 ?
Positions cardiaques avec réanimation réussie (I46.0) sont conformes à la tendance normale. Les données semblent vraiment correctes.
En outre, il existe une catégorie »Arrêt cardiaque, non spécifié." Nous y voyons presque le même saut que dans Décès dû à une insuffisance cardiaque soudaine.

Dans quelle mesure les diverses catégories sont des doublons ou des chevauchements, je ne sais pas, toutes les conceptions de bases de données ne sont pas aussi concluantes.
Ces graphiques sont générés sur https://corih.de/KBV-Daten/index.php?ohneuberhang=1&uberproz=0&mind=0&icd=I46
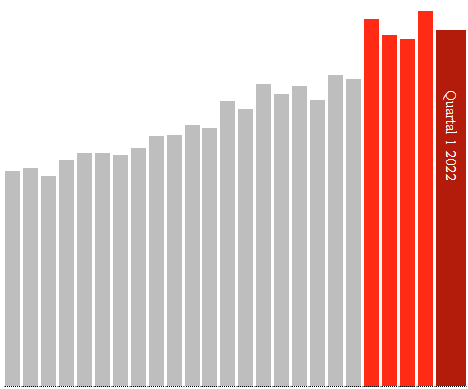
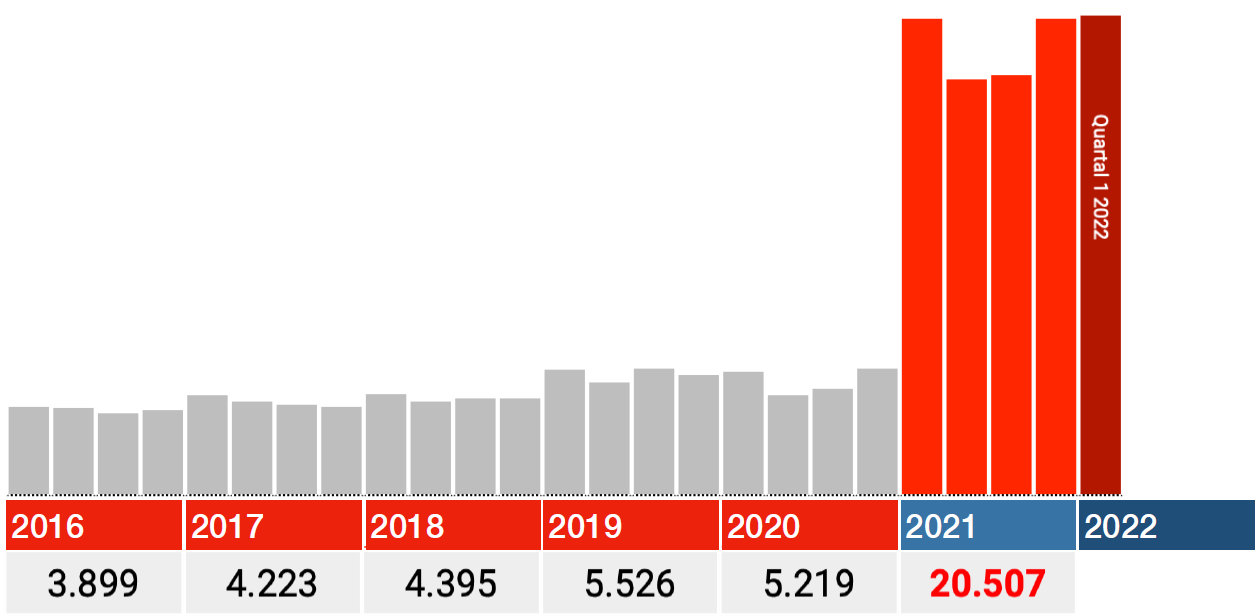
Les trimestres de 2021 sont corrects
Les données pour 2021 semblent également correctes. Il suffit donc de regarder les barres rouges dans les graphiques ci-dessous: chaque barre correspond à un trimestre 2021, la barre rouge foncé au 1er trimestre 2022.
Dans toutes les catégories, le coup le plus dur tombe immédiatement au premier trimestre de 2021, après quoi les chiffres retombent au T2 et à partir de là augmentent à nouveau au T3 et au T4.
S’il y a des idées sur la façon dont les soins retardés, les confinements ou le long covid peuvent causer cela, j’aimerais avoir de vos nouvelles. Avec les vaccinations, je peux penser à quelque chose : les plus vulnérables ont été piqués en premier. L’Allemagne a commencé à le faire fin décembre 2020.
d’autres personnes
Comment cela se déroule-t-il?
Je suis très curieux de connaître toute l’histoire avec laquelle toutes les questions ci-dessus sont répondues:
- Comment la pollution se retrouve-t-elle dans l’ensemble de données?
- En quoi la susceptibilité à l’erreur (degré de contamination) peut-elle différer autant d’un code à l’autre ?
- Comment certains polluants peuvent-ils afficher une tendance stable/descendante et d’autres une tendance à la hausse?
- Si les données n’étaient pas complètes, les données de l’I46.1 (mort subite d’origine cardiaque) sont-elles correctes?
Avant de commencer à spéculer davantage: d’abord la transparence et les données ouvertes afin que nous puissions savoir avec des recherches indépendantes ciblées si les vaccinations ont quelque chose à voir avec cela. Il existe suffisamment de preuves circonstancielles.
"... le plus gros coup immédiatement au premier trimestre de 2021, après quoi les chiffres rechutent au T2 et à partir de là augmentent à nouveau au T3 et T4 .... S’il y a des idées sur la façon dont les soins retardés, les confinements ou le long covid peuvent causer cela, j’aimerais avoir de vos nouvelles.
Je pense qu’il y a beaucoup de variables. La variante Alfa est devenue dominante surtout en Q1. Le taux de contagiosité a augmenté rapidement à 50% et en même temps, en particulier B.1.1.7, s’est avéré beaucoup plus écœurant que la variante précédente.
Après cela, Delta est devenu dominant, mais à ce moment-là, vous avez des influences possibles de vaccinations et de confinement, de résistance accumulée et ainsi de suite. Pour moi, la hausse au T3 est plus déroutante.
Un autre problème avec les Q1 sont parfois les séquelles de la fin du T4 de l’année précédente. Les gens tombent malades plus souvent dans un Q1 précisément parce que beaucoup de résistance disparaît dans Q4, hiver, nourriture, assis à la maison, etc.
Ce ne sont pas vraiment des variables typiques de l’insuffisance cardiaque ou « moins de 24 heures après l’apparition des symptômes, non spécifié ailleurs ». En regardant les Q1 précédents, celui-ci semble assez brillant.
Ik ben bang dat de data vervuiling/foute invoer een plausibele verklaring is.
Je hebt te maken met overheidsinstanties. Ik werk er ook voor en als er ergens slecht met data wordt omgegaan is het bij overheden. Waarom doen ze daar niets aan? Ik geef al 20 jaar oplossingen aan voor simpele registraties die al 20 jaar fout blijven gaan door verkeerde processen en geen! databeheer, ik krijg gelijk en men vindt het prachtig, maar krijg vervolgens geen poot aan de grond en ze doen niets.
Een volgend probleem kan zijn dat door de spontane focus op data en cijfers opeens iedereen serieuzer cijfers is gaan invoeren. Ik heb bijv. voor CBS-statistieken jarenlang cijfers verzonnen omdat het gevraagde nergens in onze bestanden voorkwam. Men eiste een antwoord en kreeg er een, voor de bron is de data waardeloos dus sowhat. En nooit was er een factcheck door het CBS door bijvoorbeeld de cijfers ook elders of anders op te vragen.
En waarom doet de overheid hier nooit wat aan of willen ze er zelfs niets aan doen? Ten eerste heeft het veel nut voor de overheid op niet te beschikken over goede data. (scheelt weer zwarte inkt voor balkjes)Je kan dan namelijk zonder problemen (blijkbaar) gewoon miljoenen blijven verkwisten en niemand doet er wat aan of snapt er iets van. Ten tweede kan je zo het makkelijkst de waarheid verdoezelen. Stel de vaccinatie veroorzaakt slecht 5% meer doden, op zich erg genoeg om er mee te stoppen natuurlijk. Maar als de cijfers zo gaan afwijken als nu dan worden ze ongeloofwaardig en verdwijnen de “echte” 5% door het instorten van de bijv. 17% wanneer het rapport van Tom Lausen onderuit gehaald kan worden voor wat betreft die 17%. Vervolgens als het data-probleem bekend wordt, opgelost kan worden, hoeft hij ook niet meer terug te komen met de “echte” 5%. De geloofwaardigheid is verspeeld.
De overheid houdt zichzelf ook bewust dom. In het land der blinden is eenoog koning. Bijvoorbeeld door een management aan te stellen die niets weet van de inhoud en door de echte inhoudsdeskundigen systematisch weg te promoveren in doodlopende functies. Dit gebeurt sinds 2004 bij IenM structureel, vandaar ook het ene na het andere schandaal of blunders en budgetoverschrijdingen van miljoenen in een jaar. Kijk ook bijv. naar de stikstof aanpak, verkeerd geplaatste sniffers en slechte data en vervolgens een model dat je precies zo kan instellen dat de boeren die jij weg wilt hebben als pieken in de kaart komen te staan. Ook de visserij wordt weer aan de schandpaal gezet door verkeerde data enz. enz. Data is een wapen tegen de bevolking en ze zetten het overal in. En je hoeft er alleen maar stom voor te zijn, de belangrijkste competentie om ambtenaar te zijn naast een universitaire opleiding in kantklossen.
Je bevestigt mijn ergste vermoedens…
En règle générale, on prétend maintenant que ces données ne sont pas appropriées pour tirer des conclusions (dans ce cas, sur les tendances des causes de décès), alors que pendant toute la pandémie, le nombre de tests corona positifs a été utilisé sans aucune critique comme s’il s’agissait d’un échantillon représentatif de la population. Si les données sont complètes (et sinon, elles doivent simplement être complétées), il me semble que le risque de biais dans ce cas est beaucoup plus faible que dans le cas des tests corona.
Soit dit en passant, je peux très bien imaginer que les données n’ont pas été accidentellement livrées de manière incorrecte. En donnant aux données l’apparence d’une augmentation irréaliste, toute l’histoire devient immédiatement suspecte. Bien qu’en Allemagne seulement, l’association avec l’AfD soit en fait ausreicht pour cela.
Kerryn Phelps toparts en politicus in Australië, ernstig en blijvend (?) ziek na 2e Pfizer-vaccinatie. Onthuld dat artsen in haar land worden gecensureerd op straffe van hoge boetes en verlies van registratie.
https://www.smh.com.au/politics/federal/not-anti-vaxxers-dr-kerryn-phelps-says-she-suffered-covid-vaccine-injury-calls-for-more-research-20221220-p5c7ry.html
De ’toparts’ Kerryn Phelps is overigens groot voorstander van lockdowns, vaccinatie- en mondmaskerplicht, ook binnenshuis. Zij riep in september 2022 nog op om alle strenge covidmaatregelen opnieuw in te voeren!
Met zulke hardleerse medici past geen medelijden. Karma is…
Ik heb het artikel uit de Herald vertaald https://virusvaria.nl/oproep-van-australische-hardliner-met-vaccinschade-wij-zijn-geen-anti-vaxxers/
Was de reden om Nederlandse oversterftedata te anonimiseren wellicht om te voorkomen dat het Nederlandse volk er via BSN nummers achterkomt dat slechts een klein deel van Nederlandse politici zich daadwerkelijk heeft laten inspuiten met Spike-eiwit mRNA, net als werd opgemerkt in Japan:
https://twitter.com/riseupandresist/status/1599160471046983680
Daarnaast moet verder worden gekeken dan alleen (over)sterfte; ook toename van ziekte zelf (hart-en vaat, long, neuro, etc.).