Die identifizierten Spektakulärer Aufstieg der plötzlichen und unerwarteten deutschen Todesfälle im Jahr 2021 wären auf Fehler in den Daten zurückzuführen. Es waren sicherlich unglaublich sensationelle Figuren und gleichzeitig: Wenn etwas so selten ist wie "plötzlicher Tod", dann werden Sie bald Verdoppelungen oder mehr sehen, wenn sich in diesem Bereich etwas bewegt. Darüber hinaus stammen die Daten von einem exzellenten Regierungsinstitut und der beteiligte Analyst Tom Lausen ist in der Materie bestens versiert. Mehrere unabhängige Überprüfungen bestätigten seine Ergebnisse weitgehend.
Natürlich gab es auch viel Stottern: Verschiedene Faktenchecks gehen nicht weiter als dass Tom Lausens Analyse falsch war und die Zahlen nicht für eine solche Analyse gedacht waren. Es wird auch behauptet, dass die Daten bewusst in einer Weise angefordert wurden, die nur zu diesem Ergebnis führen konnte. Kurz gesagt: Panik bei vielen Faktenprüfern, Ausnahmen Abgesehen davon.
Aber: Es scheint etwas los zu sein. Wo sind wir darauf hereingefallen? Haben wir uns wirklich auf etwas eingelassen? Dann überzeugen wir uns selbst.
Was genau wurde angefordert?
Drei Datenpakete wurden angefordert. Die ersten beiden Datenpakete waren erst 2021 versichert. Dies könnte daher keine Sterblichkeitszahlen aus früheren Jahren enthalten, was das Fehlen von Sterblichkeitscodes bis 2021 erklären würde. Aber beim dritten Paket ging es wirklich um alle Versicherten 2016-2021.
Sie sind dafür verantwortlich, eine Aufschlüsselung der Häufigkeit aller ICD-Codes aller Versicherten – mit Ausnahme der Versicherten aus Paket 1 – für den Zeitraum 2016 bis 2021, sofern auch für 2022 verfügbar, an Quartale zu senden. Die Daten müssen mit V und G abgerufen werden.
Anforderung von Bestätigungsdaten
Paket 3. Sie beantragen die Übermittlung einer Auf,istung der Häufigkeit aller ICD-Codes aller Versicherten – ohne die Versichtertenmenge aus Paket 1 – für de Zeitraum 2016 bis 2021, falls anteilig vorliegend auch für 2022, nach Quartalen. Die Datenabfrage soll mit V und G erfolgen.

Nun wird behauptet, Paket 3 sei unvollständig zugestellt worden: Die Versicherten, die bereits vor 2021 verstorben waren, seien nicht darunter, es würden nur Personen enthalten, die 2021 noch als versichert gemeldet waren. Sie konnten also keine Sterblichkeitscodes in den Jahren 2016-2020 haben ... Daher die absurden Unterschiede zu 2021. Willkür oder Missverständnis, das lassen wir in der Mitte.
Doch auch das stimmt nicht.
Wir gehen für einen Moment davon aus, dass die Daten tatsächlich Menschen betrafen, die im Jahr 2021 noch am Leben waren. Offenbar wurde der 1. Januar 2021 als Benchmark-Datum herangezogen. Wäre der 31. Dezember gewählt worden, wäre zumindest nach dieser Argumentation kein Tod sichtbar gewesen. Schließlich können Sie davon ausgehen, dass jemand, der einmal verstorben ist, nicht mehr als versicherte Person gilt. Am 31. Dezember wurden alle in diesem Jahr verstorbenen Personen als Versicherte abgemeldet. Dann haben Sie nichts mehr zu berichten, wenn Sie geradlinig genug denken.
Wenn jemand, der die Daten erheben musste, das erkannt hat, fällt zumindest auf, dass er 2016-2020 nicht mitgenommen oder aber gefragt hat, was die Absicht war.
Vor diesem Hintergrund zeigt die Gesamtgrafik etwas Seltsames:
Unter den Menschen, die 2021 noch am Leben waren, starben 2016-2020 anderthalb Mal so viele wie 2021 selbst.
Lesen Sie das noch einmal.
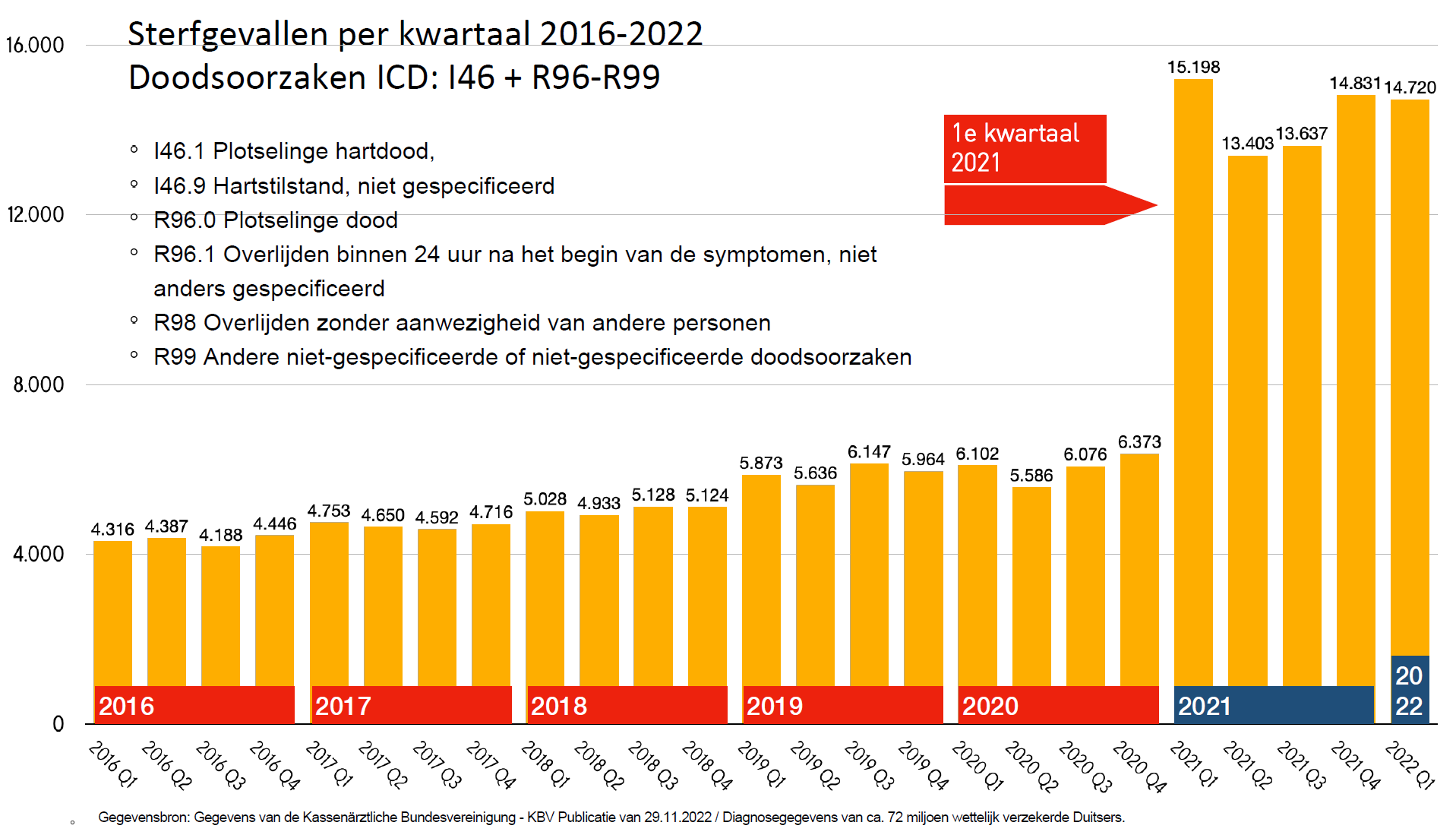
Dies wird von Experten bequem als "Eingabefehler" erklärt. Wir verstehen das; Schließlich können die Impfstoffe nicht sein. Aber dann ist es ein Eingabefehler, der immer einfacher gemacht wurde, wie der leicht steigende Trend von 2016-2019 zeigt. Wir können davon ausgehen, dass sich dieser Trend im Jahr 2021 fortsetzen wird. Dann sind etwa 40% der vom Paul-Ehrlich-Institut für 2021 bereitgestellten Daten nur Fake, weil es keinen Grund zu der Annahme gibt, dass diese Eingabefehler dort plötzlich nicht mehr aufgetreten sind ...
Und wenn Daten aus den Jahren vor 2021 Verstorbene überhaupt nicht einbezogen werden, woher kommen dann diese "Eingabefehler" eigentlich!?
40% "Eingabefehler", ist das nicht selbst für die Medizinbranche sehr viel?
Wenn es an der Quelle falsch eingegeben wird, ist es nicht leicht herauszufinden. Diese Quelle sind die Ärzte: Es handelt sich um Ansprüche (Kostenberichte), die Ärzte an Versicherer senden. Deshalb denken wir auch an Betrug statt an Fehler. Ärzte hätten bewusst mehr Handlungen aufgegeben, als sie tatsächlich durchführten. Dies wirft auch Fragen und Einwände auf:
- Dies sind keine Handlungen, es sind Todesumstände, wie "verstorben ohne andere Personenanwesenheit".
- Bekommen Ärzte zusätzliches Geld, wenn jemand stirbt, ohne dass andere Personen anwesend sind...?
- Wenn Sie als Arzt etwas steigern wollen, tun Sie dies mit dem plötzlichen Tod Ihrer eigenen Patienten (Ihr Kundenstamm, Sie reduzieren Ihre Praxis) oder ticken Sie extra eingewachsene Zehennägel, Stiche oder Ohren- und Augeninfektionen? Es gibt zweifellos weniger drastische, häufigere, zeitaufwändigere Handlungen als die Beobachtung eines plötzlichen Todes, der nicht mehr durchgeführt werden kann.
Ist es manchmal mit den Krankenkassen oder mit dem Bundesschirm?
Ein weiterer Punkt der Verschmutzung können die Krankenkassen selbst sein. Sie dürfen keine Megagewinne machen, so dass sie Kosten verursachen könnten, um die Prämien auf dem neuesten Stand zu halten. Selbst dann scheinen Todesfälle nicht der geeignete Kostenposten zu sein, zumindest wenn Sie es nicht hervorheben wollen.
Zurück zur Frage: Wie kommt diese enorme Verschmutzung in die Daten? Liegt die Schuld vielleicht am Forschungsinstitut für Impfstoffe und Biomedizin, dem Paul-Ehrluch-Institut, das alle Daten gesammelt hat? Kardinalfehler werden auch an Instituten gemacht, die wir an unseren eigenen Instituten immer wieder gesehen haben.
Es ist gut zu erkennen, dass die Situation in Deutschland anders ist als in den Niederlanden: Ein "Bundesinstitut" sammelt dort die Daten der Bundesländer. Jedes Bundesland hat eine eigene Krankenkasse oder Kassenärtzlichen Vereinigung (NRW hat zwei). Es gibt also 17 KV's, vereint in einer Bundesvereinigung.
Faktor 17
Wenn das Bundesinstitut fälschlicherweise Daten von allen bis auf eines der Institute angefordert hat, könnte dies diese Grafik erklären.
Dann gibt es ein Institut, das auch 2016-2019 weitergegeben hat, daher kommt diese Handvoll Daten. Die restlichen sechzehn haben erst 2021 eingereicht.

Indikation
Kann das jemals rekonstruiert werden? Das Institut mag die Frage direkt weitergeleitet haben und nur 1 der Siebzehn verstand die Frage so, wie sie beabsichtigt war, der Rest nur auf Autopilot (nach Paket 1 und Paket 2) stellte sich auch Paket drei nur für 2021 heraus.
Beim Zusammenführen der Daten gibt es wieder keine Aufmerksamkeit. Ein datenverantwortliches Regierungsinstitut sollte darauf achten, dass Datensätze nicht konsistent zusammengestellt werden. Gen-Input-Kontrolle? Keine Ausgangsregelung?
Dieser Faktor von 17 sollte dann mehr oder weniger auch für andere Kodizes gelten. Wir haben einen Faktor von 16,7 gesehen, was damit übereinstimmt. Bei den anderen Codes sollte dies mehr oder weniger der Fall sein. Mit einer gewissen Marge sollten sie in der Größenordnung zwischen 15 und 20 liegen.
Das ist nicht der Fall. Die Faktoren dort sind ca. 10, 6 und 3 (nur Faktor 3 Grafik gezeigt, 293% um genau zu sein). Keineswegs ein Faktor von 17 und die Bundesländer werden nicht so unterschiedlich sein, oder?
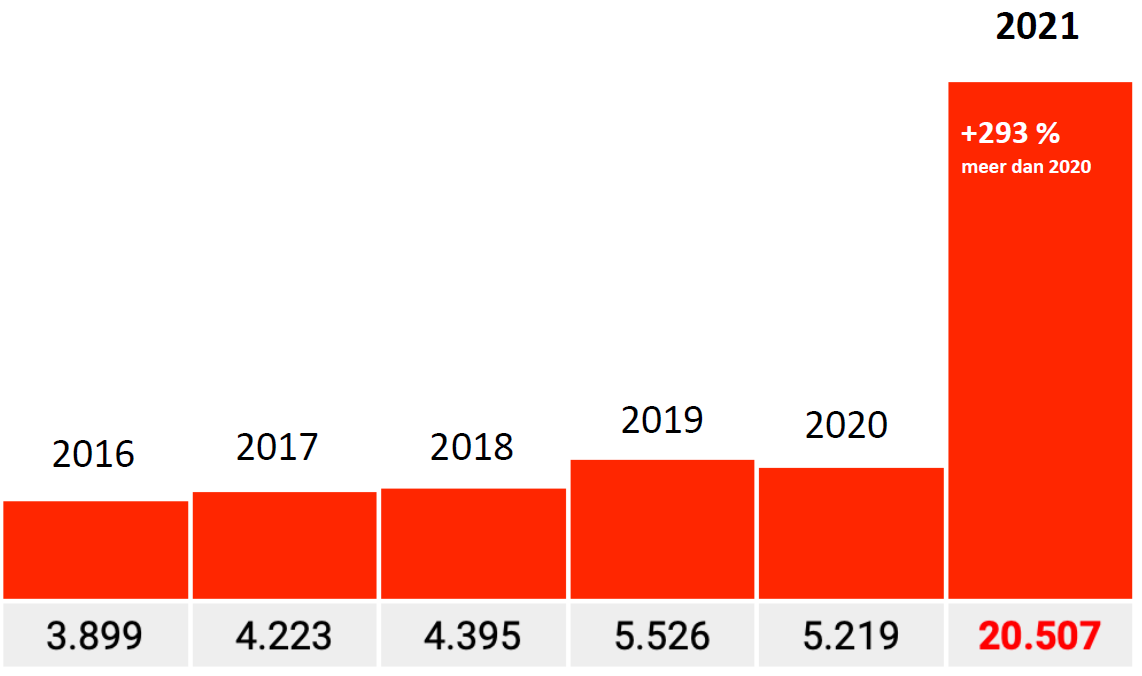
Faktor 0,2
Soviel zu den absurden Unterschieden. Schauen wir uns Code I46.1 an: Tod durch plötzliche Herzinsuffizienz, dann beträgt der Unterschied plötzlich nur noch etwa 20% zu 2020. Welcher Systemfehler oder "Eingabefehler" könnte wieder gemacht worden sein? Plötzliche Herzinsuffizienz ist eine echte Todesursache, die anderen Codes sind Umstände, vielleicht wurde das anders behandelt? Dieser Code wurde auch später hinzugefügt.
Wäre dies die einzige Grafik, in der die Jahre 2016-2020 korrekt enthalten sind? In jedem Fall erscheint eine Steigerung von 15-20% glaubwürdiger als eine von 1700%. Die Botschaft wird nicht weniger dringlich: Untersucht das! (und in der Zwischenzeit stoppen Sie diese Impfung auf nichts).
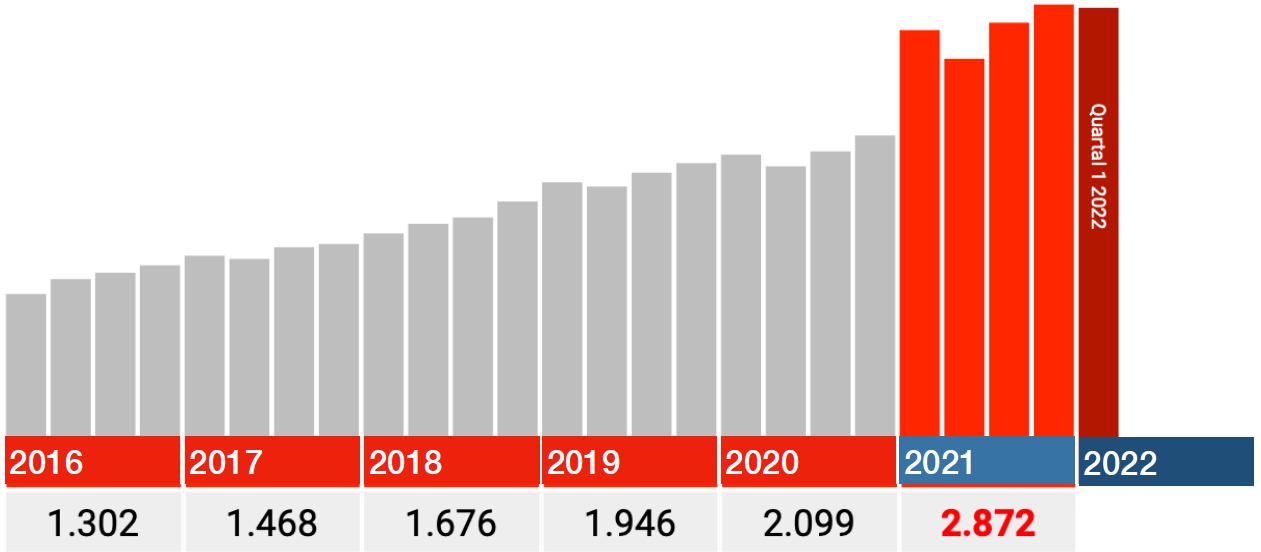
Wie funktionieren andere I.46-Codes?
Herzpositionen mit erfolgreicher Reanimation (I46.0) entsprechen dem normalen Trend. Daten scheinen wirklich in Ordnung zu sein.
Darüber hinaus gibt es eine Kategorie "Herzstillstand, nicht spezifiziert." Darin sehen wir fast den gleichen Sprung wie in Tod durch plötzliche Herzinsuffizienz.

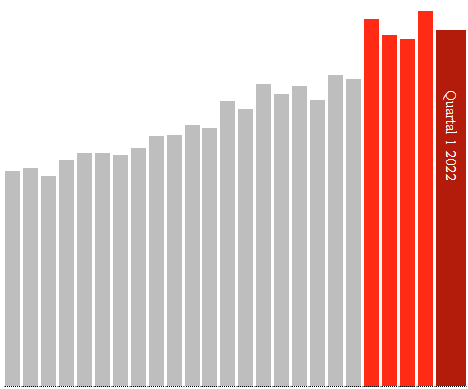
Inwiefern die verschiedenen Kategorien Doppelungen oder Überschneidungen sind, weiß ich nicht, nicht jedes Datenbankdesign ist gleichermaßen schlüssig.
Diese Diagramme werden generiert am https://corih.de/KBV-Daten/index.php?ohneuberhang=1&uberproz=0&mind=0&icd=I46
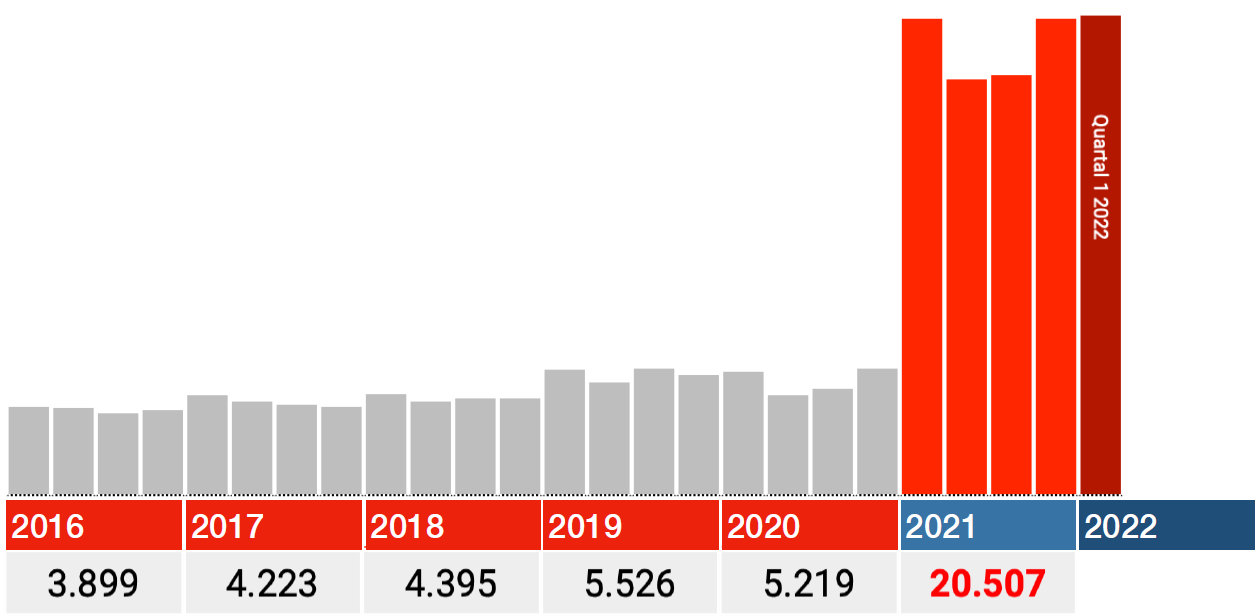
Die Quartale 2021 stimmen
Die Daten für 2021 scheinen ebenfalls korrekt zu sein. Schauen Sie sich also nur die roten Balken in den Grafiken unten an: Jeder Balken ist ein Quartal 2021, der dunkelrote ist Q1 2022.
In allen Kategorien fällt der größte Schlag sofort im ersten Quartal 2021, danach fallen die Zahlen in Q2 zurück und steigen von dort aus wieder in Q3 und Q4.
Wenn es irgendwelche Ideen gibt, wie verzögerte Pflege, Lockdowns oder Long Covid dies verursachen können, würde ich gerne von Ihnen hören. Bei Impfungen fällt mir etwas ein: Die Schwächsten wurden zuerst gestochen. Deutschland hat damit Ende Dezember 2020 begonnen.
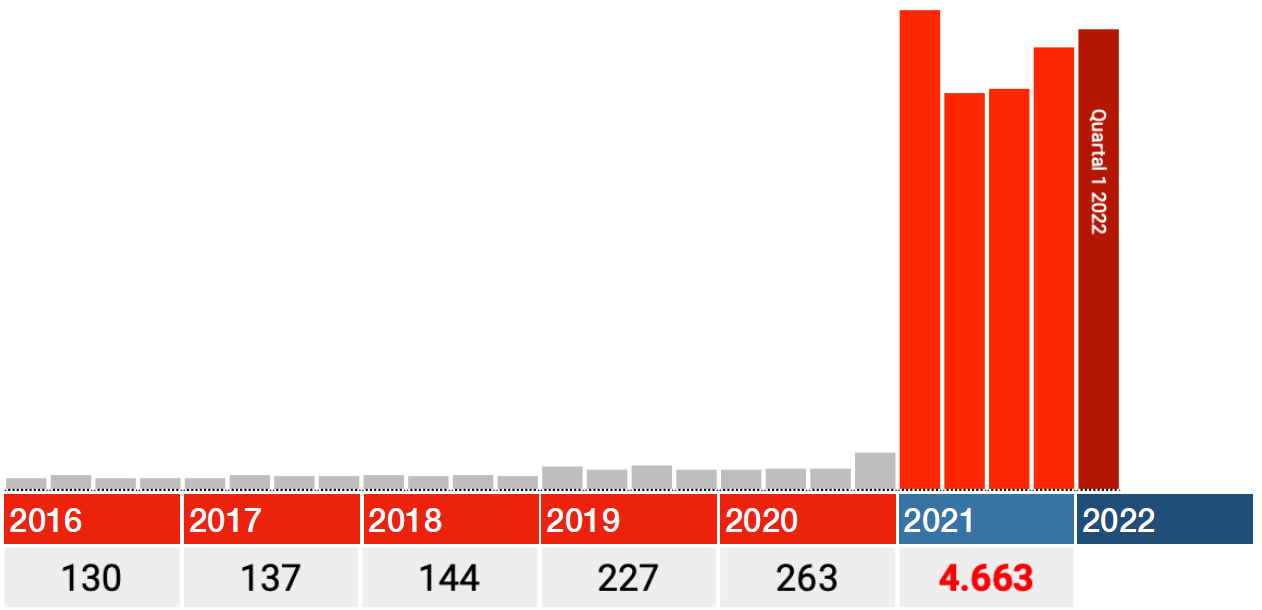
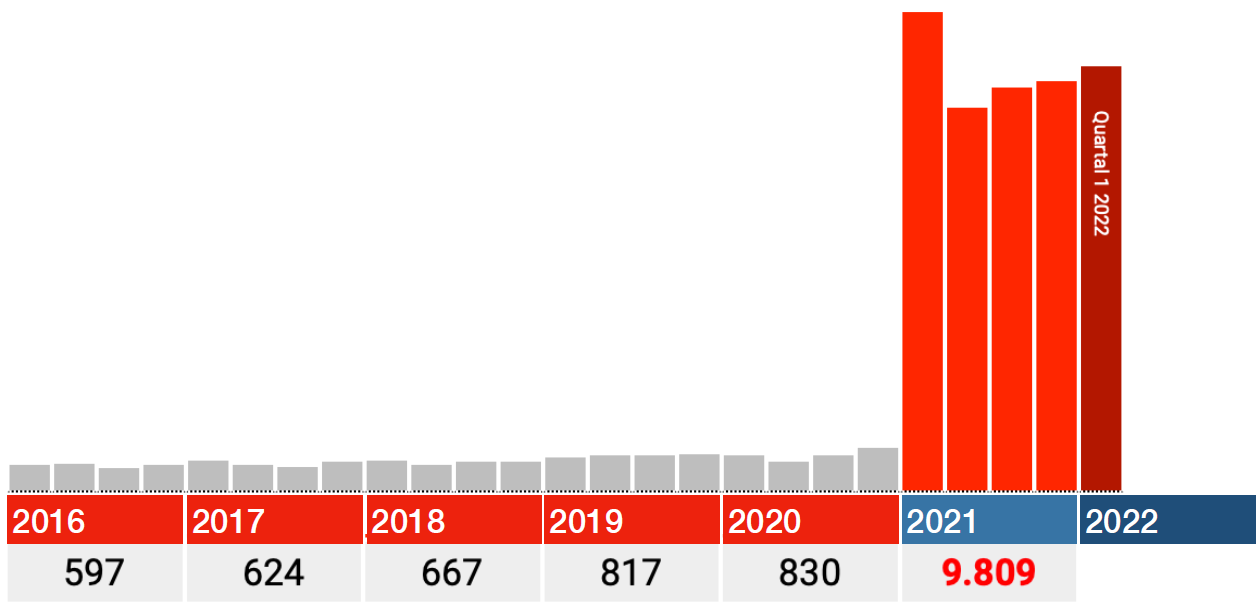
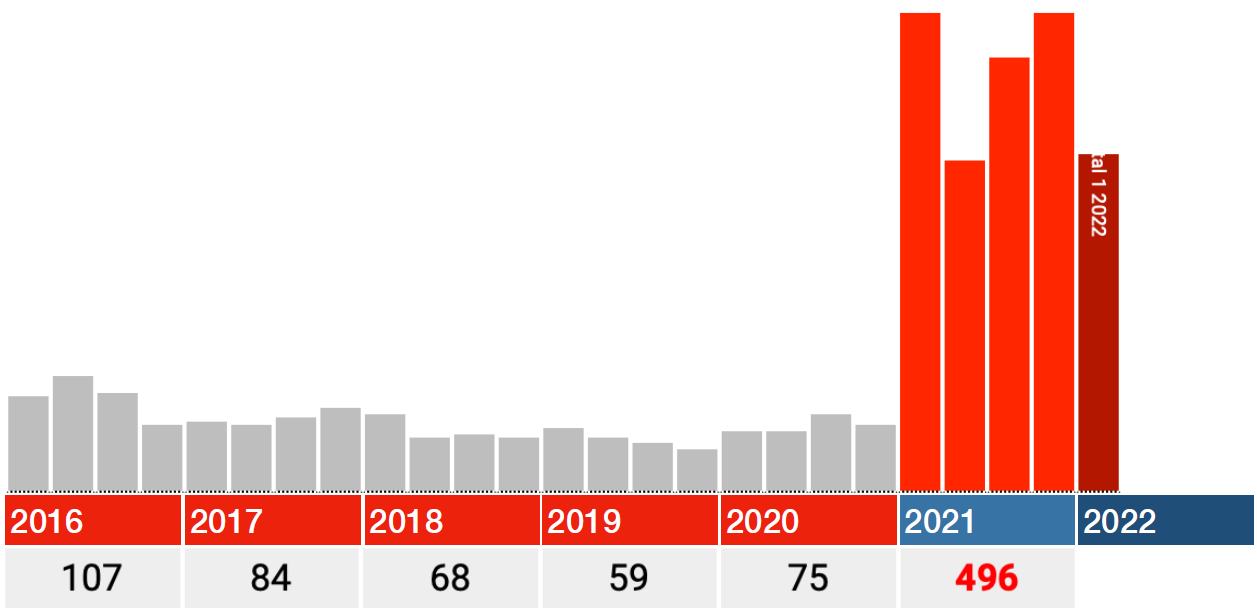
von anderen Personen
Wie entwickelt sich das?
Ich bin sehr gespannt auf die ganze Geschichte, mit der alle oben genannten Fragen beantwortet werden:
- Wie landet die Verschmutzung im Datensatz?
- Wie kann sich die Fehleranfälligkeit (Verschmutzungsgrad) je nach Code so stark unterscheiden?
- Wie können einige Schadstoffe einen stabilen/absteigenden Trend zeigen und andere einen steigenden Trend?
- Wenn die Daten nicht vollständig wären, sind die Daten aus dem I46.1 (plötzlicher Herztod) korrekt?
Bevor wir weiter spekulieren: Zunächst Transparenz und offene Daten, damit wir mit gezielter unabhängiger Forschung herausfinden können, ob die Impfungen überhaupt etwas damit zu tun haben. Es liegen hinreichende Indizien vor.
"... der größte Schlag sofort im ersten Quartal 2021, danach fallen die Zahlen in Q2 zurück und steigen von dort aus wieder in Q3 und Q4 .... Wenn es Ideen gibt, wie verzögerte Pflege, Lockdowns oder Long Covid dies verursachen können, würde ich gerne von Ihnen hören. "
Ich denke, es gibt viele Variablen. Die Alfa-Variante dominierte vor allem in Q1. Die Ansteckungsrate stieg schnell auf 50% an und erwies sich gleichzeitig als viel widerlicher als die vorherige Variante, insbesondere B.1.1.7.
Danach kam Delta als dominant, aber zu diesem Zeitpunkt haben Sie mögliche Einflüsse von Impfungen und Lockdown, Aufbau von Resistenzen und so weiter. Für mich ist der Anstieg in Q3 rätselhafter.
Ein weiteres Problem bei Q1s sind manchmal Nachwirkungen vom Ende des 4. Quartals des Vorjahres. Menschen werden in einem Q1 häufiger krank, gerade weil in Q4, Winter, Essen, zu Hause sitzen usw. viel Widerstand verschwindet.
Das sind nicht wirklich typische Variablen für Herzinsuffizienz oder "Weniger als 24 Stunden nach Beginn der Symptome, nicht anders angegeben". Wenn man sich frühere Q1's ansieht, sieht dieser ziemlich hell aus.
Ich fürchte, dass die Datenverschmutzung / falsche Eingabe eine plausible Erklärung ist.
Sie haben es mit Regierungsbehörden zu tun. Ich arbeite auch dafür, und wenn es irgendwo einen schlechten Deal mit Daten gibt, dann mit Regierungen. Warum tun sie nichts dagegen? Seit 20 Jahren biete ich Lösungen für einfache Registrierungen, die seit 20 Jahren aufgrund falscher Prozesse schief gehen und keine! Datenmanagement, ich habe Recht und die Leute lieben es, aber dann bekommen sie keinen Fuß auf den Boden und sie tun nichts.
Ein weiteres Problem könnte sein, dass durch die spontane Fokussierung auf Daten und Zahlen plötzlich jeder begonnen hat, ernstere Zahlen einzugeben. Zum Beispiel habe ich jahrelang Zahlen für CBS-Statistiken erfunden, weil die Anfrage nirgendwo in unseren Akten stand. Sie verlangten eine Antwort und bekamen eine, für die Quelle sind die Daten also wertlos. Und es gab nie einen Faktencheck durch CBS, indem zum Beispiel die Zahlen an anderer Stelle oder anderweitig angefordert wurden.
Und warum unternimmt die Regierung nie etwas dagegen oder will gar nichts dagegen tun? Erstens ist es für die Regierung sehr nützlich, keine guten Daten zu haben. (spart schwarze Tinte für Balken) Man kann dann (scheinbar) weiterhin problemlos Millionen verschwenden und niemand tut etwas dagegen oder versteht etwas davon. Zweitens ist dies der einfachste Weg, die Wahrheit zu vertuschen. Angenommen, die Impfung verursacht nur 5% mehr Todesfälle, was an sich schon schlimm genug ist, um natürlich aufzuhören. Aber wenn die Zahlen anfangen, so abzuweichen, wie sie es jetzt tun, werden sie unplausibel, und die "echten" 5% verschwinden aufgrund des Zusammenbruchs beispielsweise der 17%, wenn Tom Lausens Bericht in Bezug auf diese 17% untergraben werden kann. Wenn dann das Datenproblem bekannt wird, gelöst werden kann, muss er nicht mit den "echten" 5% zurückkommen. Die Glaubwürdigkeit ist verloren gegangen.
Die Regierung hält sich auch absichtlich dumm. Im Land der Blinden ist der Einäugige König. Zum Beispiel durch die Ernennung eines Managements, das nichts von den Inhalten weiß, und durch die systematische Förderung der echten Content-Experten in Sackgassen. Dies geschieht strukturell seit 2004 bei IenM, daher ein Skandal nach dem anderen oder Fehler und Budgetüberschreitungen in Millionenhöhe in einem Jahr. Schauen Sie sich auch den Stickstoffansatz, falsch platzierte Schnüffler und schlechte Daten an und dann ein Modell, das Sie genau so einstellen können, dass die Bauern, die Sie loswerden möchten, als Spitzen in der Karte angezeigt werden. Die Fischerei wird auch wieder durch falsche Daten usw. usw. an den Pranger gestellt. Daten sind eine Waffe gegen die Bevölkerung und sie werden überall eingesetzt. Und man muss einfach dumm sein dafür, die wichtigste Kompetenz, um Beamter zu sein, neben einer universitären Ausbildung im Klöppeln.
Sie bestätigen meinen schlimmsten Verdacht...
Typischerweise wird nun behauptet, dass diese Daten nicht geeignet seien, Rückschlüsse (in diesem Fall über die Entwicklung der Todesursachen) zu ziehen, während während der gesamten Pandemie die Anzahl der positiven Corona-Tests kritiklos wie eine repräsentative Stichprobe der Bevölkerung herangezogen wurde. Wenn die Daten vollständig sind (und wenn nicht, müssen sie einfach ergänzt werden), scheint mir, dass die Wahrscheinlichkeit einer Verzerrung in diesem Fall um ein Vielfaches geringer ist als bei Corona-Tests.
Ich kann mir übrigens gut vorstellen, dass die Daten nicht versehentlich falsch geliefert wurden. Indem man den Daten den Anschein eines unrealistisch starken Anstiegs gibt, wird die ganze Geschichte sofort verdächtig. Obwohl allein in Deutschland die Assoziation mit der AfD dafür eigentlich ausreicht.
Kerryn Phelps Top-Ärztin und Politikerin in Australien, schwer und dauerhaft (?) krank nach 2. Pfizer-Impfung. Enthüllte, dass Ärzte in ihrem Land unter Strafe hoher Geldstrafen und Verlust der Registrierung zensiert werden.
https://www.smh.com.au/politics/federal/not-anti-vaxxers-dr-kerryn-phelps-says-she-suffered-covid-vaccine-injury-calls-for-more-research-20221220-p5c7ry.html
Die "Top-Ärztin" Kerryn Phelps ist auch eine starke Befürworterin von Lockdowns, Impfungen und Mundmaskenpflicht, auch in Innenräumen. Im September 2022 forderte sie, alle strengen Covid-Maßnahmen wieder einzuführen!
Mit solch hart gelernten Medizinern passt kein Mitleid. Karma ist...
Ich habe den Artikel aus dem Herald übersetzt https://virusvaria.nl/oproep-van-australische-hardliner-met-vaccinschade-wij-zijn-geen-anti-vaxxers/
War der Grund für die Anonymisierung der niederländischen Übersterblichkeitsdaten vielleicht, um zu verhindern, dass die Niederländer über BSN-Zahlen herausfinden, dass nur einem kleinen Teil der niederländischen Politiker tatsächlich Spike-Protein-mRNA injiziert wurde, genau wie in Japan festgestellt wurde:
https://twitter.com/riseupandresist/status/1599160471046983680
Darüber hinaus müssen wir über die (Über-)Sterblichkeit hinausblicken; auch Zunahme der Krankheit selbst (Herz-Kreislauf, Lunge, Neuro, etc.).