De gesignaleerde spectaculaire stijging van plotselinge en onverwachte Duitse overlijdens in 2021 zou voortkomen uit fouten in de data. Het waren op het oog zeker onwaarschijnlijk sensationele cijfers en tegelijkertijd: als iets zo weinig voorkomt als ‘sudden death’, dan zie je al snel verdubbelingen of meer als er ook maar iets beweegt op dat vlak. Daarbij: de data waren afkomstig van een excellent overheidsinstituut en de betrokken analist Tom Lausen is uitstekend thuis in de materie. Diverse onafhankelijke reviews bevestigden zijn bevindingen in grote lijnen.
Natuurlijk werd er ook hevig gesputterd: diverse factchecks komen niet verder dan dat de analyse van Tom Lausen niet klopte en dat de cijfers niet bedoeld waren voor zo’n analyse. Ook wordt beweerd dat de data opzettelijk op een manier zijn opgevraagd die alleen maar tot dit resultaat kon leiden. Kortom: paniek bij veel factcheckers, uitzonderingen daargelaten.
Maar: er lijkt wel degelijk iets aan de hand. Waar zijn we ingetrapt? Zijn we echt wel ergens ingetrapt? Dan maar zelf weer eens kijken.
Wat is er precies opgevraagd?
Er werden drie data-pakketten opgevraagd. De eerste twee data-pakketten gingen om alleen verzekerden in 2021. Daar konden dus geen sterftecijfers bij zitten van voorgaande jaren, wat het ontbreken van sterftecodes tot 2021 zou verklaren. Maar het derde pakket ging toch echt om alle verzekerden van 2016-2021.
U draagt zorg voor toezending van een uitsplitsing van de frequentie van alle ICD-codes van alle verzekerden – exclusief de verzekerden uit pakket 1 – voor de periode 2016 tot en met 2021, indien beschikbaar ook voor 2022, naar kwartalen. De gegevens moeten worden opgevraagd met V en G.
Bevestiging dataverzoek
Paket 3. Sie beantragen die Übermittlung einer Auf,istung der Häufigkeit aller ICD-Codes aller Versicherten – ohne die Versichtertenmenge aus Paket 1 – für de Zeitraum 2016 bis 2021, falls anteilig vorliegend auch für 2022, nach Quartalen. Die Datenabfrage soll mit V und G erfolgen.

Er wordt nu beweerd dat pakket 3 onvolledig is geleverd: De verzekerden die al voor 2021 waren overleden, zaten er niet bij, het zou alleen personen bevatten die in 2021 nog als verzekerde waren geregistreerd. Die konden dus geen sterftecodes hebben in 2016-2020… Vandaar de absurde verschillen met 2021. Moedwil of misverstand, dat laten we in het midden.
Toch klopt ook dat niet
We gaan er even vanuit dat de data inderdaad mensen betrof die in 2021 nog in leven waren. Kennelijk is dan als ijkdatum 1 januari 2021 genomen. Als 31 december was gekozen, was er geen enkel overlijden zichtbaar geweest, althans volgens deze redenatie. Je mag immers aannemen dat iemand, eenmaal overleden, niet meer als verzekerde wordt aangemerkt. Op 31 december zijn alle dat jaar overledenen uitgeschreven als verzekerd. Dan heb je dus niks meer om over te rapporteren als rechtlijnig genoeg denkt.
Als iemand die de data moest verzamelen zich dat heeft gerealiseerd, is het op zijn minst opvallend dat diegene 2016-2020 niet heeft meegenomen of anders heeft gevraagd wat nou eigenlijk de bedoeling was.
Met dit in het achterhoofd, vertoont de totaalgrafiek iets vreemds:
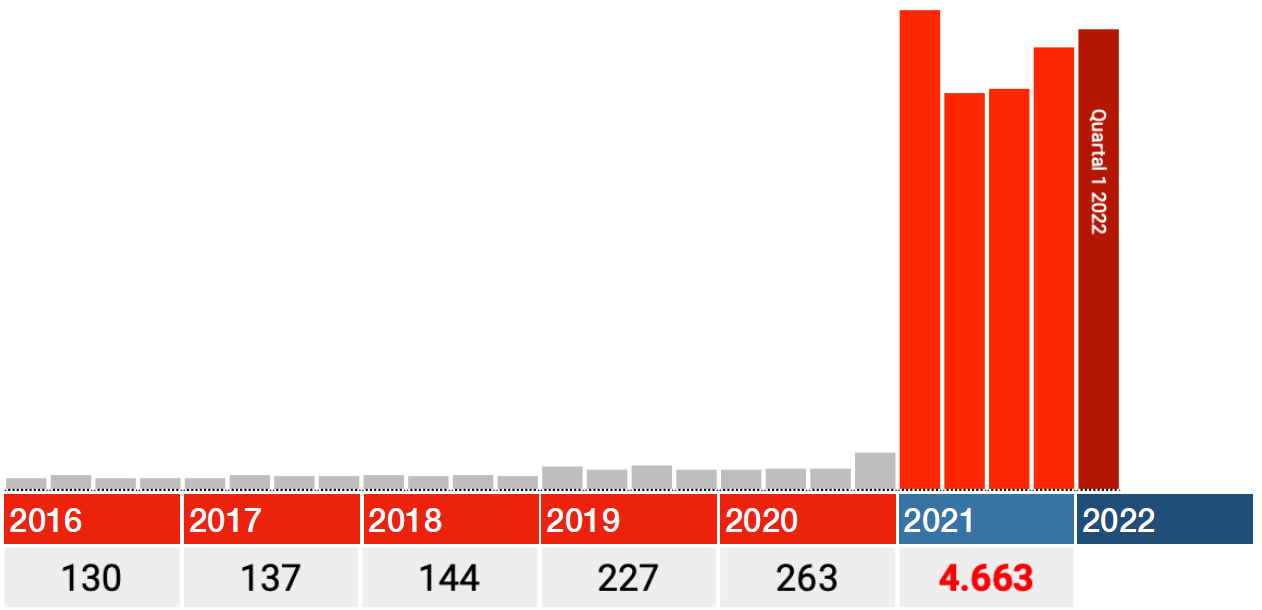
Onder de mensen die in 2021 nog leefden zijn er anderhalf keer zoveel overleden in 2016-2020 als in 2021 zelf.
Lees dat nog maar een keer.
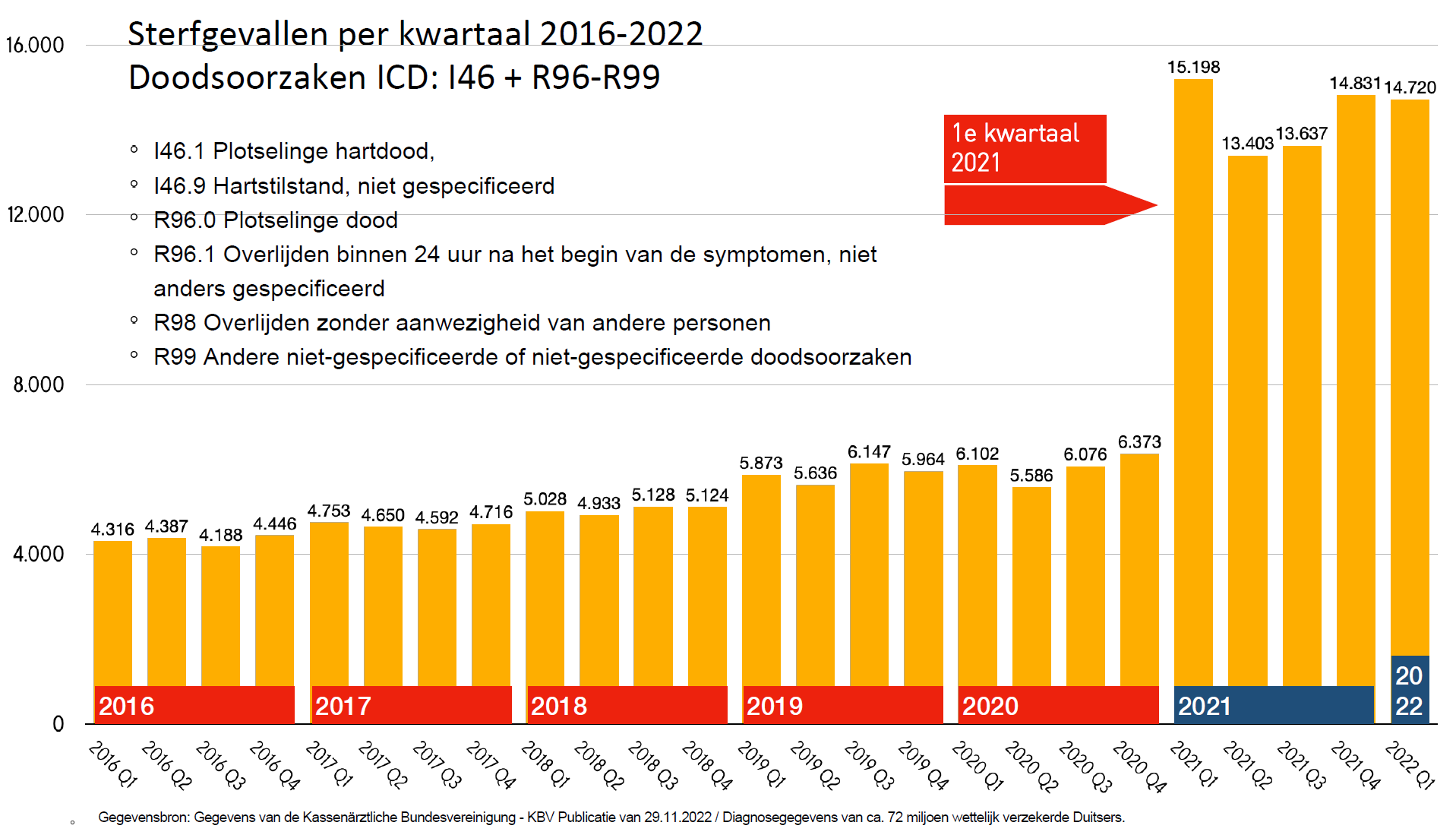
Dit wordt door experts gemakshalve verklaard als ‘invoerfout’. Daarvoor hebben we begrip; de vaccins kunnen het immers niet zijn. Maar dan betreft het wel een invoerfout die steeds makkelijker werd gemaakt, getuige de licht stijgende tendens van 2016-2019. We mogen ervan uitgaan dat die trend in 2021 doorzette. Dan is dus ca. 40% van de door het Paul Ehrlich Instituut geleverde data van 2021 gewoon fake want er is geen reden om aan te nemen dat die invoerfouten daar plotseling niet meer voorkwamen…
En als data van de jaren vóór 2021 overledenen überhaupt niet meegeleverd zijn, waar komen die ‘invoerfouten’ dan eigenlijk vandaan!?
40% ‘invoerfouten’, is dat zelfs voor de medische industrie niet erg veel?
Als het bij de bron verkeerd wordt ingevoerd is dat niet zomaar te achterhalen. Die bron zijn de artsen: het gaat om declaraties (kostenverantwoordingen) die artsen sturen aan verzekeraars. Er wordt daarom ook wel gedacht aan fraude in plaats van fouten. Artsen zouden doelbewust meer handelingen hebben opgegeven dan ze daadwerkelijk hebben uitgevoerd. Ook dat roept vragen en tegenwerpingen op:
- Het gaat hier niet om handelingen, het zijn overlijdensomstandigheden, zoals “overleden zonder andere aanwezigen”
- Krijgen artsen extra geld uitgekeerd als iemand overlijdt zonder andere aanwezigen…?
- Als je als arts wat wil opplussen, doe je dat dan met plotseling overlijden van je eigen patiënten (toch je klantenbestand, je verkleint je praktijk) of vink je extra ingegroeide teennagels aan, hechtingen of oor- en oogontstekingen? Er zijn ongetwijfeld minder ingrijpende, vaker voorkomende, meer tijd in beslag nemende handelingen beschikbaar dan het constateren van een plotseling overlijden waaraan niets meer is te doen.
Zit het soms bij de zorgverzekeraars of bij de federale koepel?
Een ander punt van vervuiling kunnen de zorgverzekeraars zelf zijn. Die mogen geen megawinsten boeken dus zouden kosten kunnen verzinnen om de premies op peil te houden. Ook dan lijken overlijdens niet de aangewezen kostenpost, tenminste als je het niet wil laten opvallen.
Terug naar de vraag: Hoe komt die enorme vervuiling dan in de data? Ligt de fout dan misschien bij het onderzoeksinstituut voor vaccins en biomedicijnen, het Paul Ehrluch Institut, dat alle data heeft verzameld? Ook bij instituten worden kardinale fouten gemaakt, dat hebben we bij herhaling gezien bij onze eigen instituten.
Het is goed om te beseffen dat de situatie in Duitsland anders is dan in NL: Een ‘federaal’ instituut verzamelt daar de data van de bondsstaten. Elke bondsstaat heeft een eigen zorgverzekeraar ofwel ‘Kassenärtzlichen Vereinigung’ (NRW heeft er twee). Er zijn dus 17 KV’s, verenigd in een Bundesvereinigung.
Factor 17
Als het federale instituut de gegevens van alle instituten behalve ééntje verkeerd heeft opgevraagd, zou dat deze grafiek kunnen verklaren.
Dan is er één insituut dat ook 2016-2019 heeft doorgegeven, daar komt dat handjevol data vandaan. De overige zestien hebben alleen 2021 ingediend.

Indicatie
Is dat ooit te reconstrueren? Het instituut heeft de vraag misschien rechtstreeks doorgespeeld en maar 1 van de zeventien heeft de vraag begrepen zoals hij was bedoeld, de rest heeft alleen op de automatische piloot (na Pakket 1 en Pakket 2) ook Pakket drie voor alleen 2021 uitgedraaid.
Bij het samenvoegen van de data is er dan opnieuw niet opgelet. Een dataverantwoordelijk overheidsinstituut zou toch moeten zien dat datasets niet consistent zijn samengesteld. Gene inputcontrole? Geen outputcontrole?
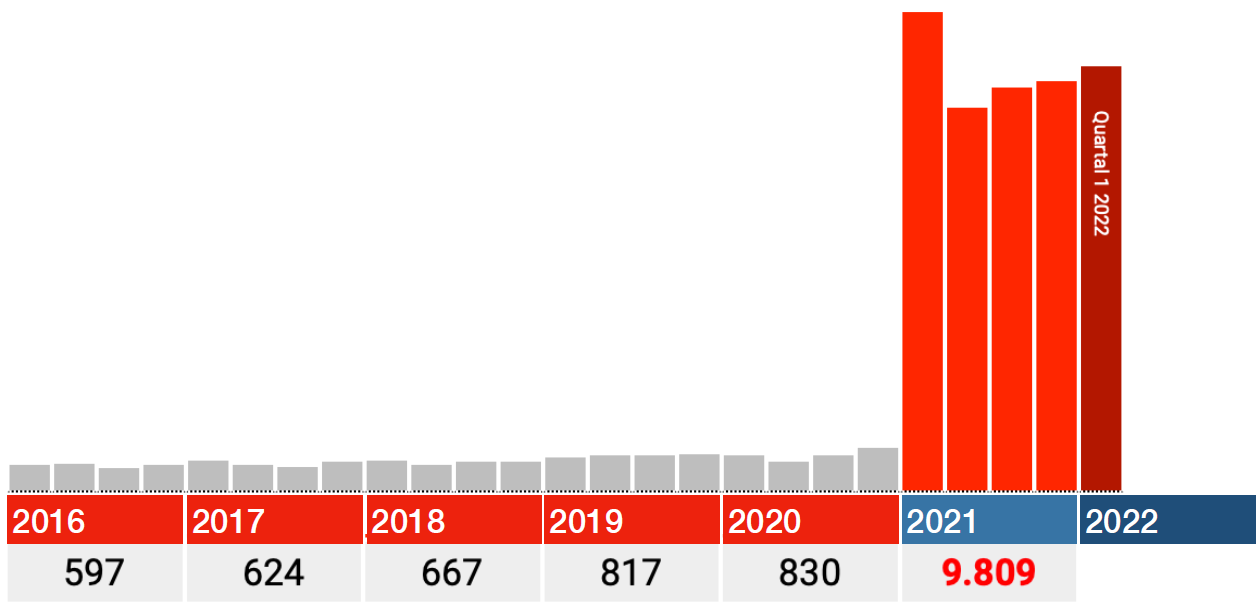
Die factor 17 zou dan min of meer ook voor andere Codes moeten opgaan. We zagen een factor van 16,7, dat ligt in lijn daarmee. Voor de andere codes zou dat dan ook min of meer moeten opgaan. Met wat marge zouden die in de orde van tussen de 15 en 20 moeten liggen.
Dat is dus niet zo. De factoren zijn daar ca. 10, 6 en 3 (alleen factor 3-grafiek getoond, 293% om precies te zijn). Bij lange na geen factor 17 en zo verschillend zullen die Bundesländer onderling toch niet zijn?
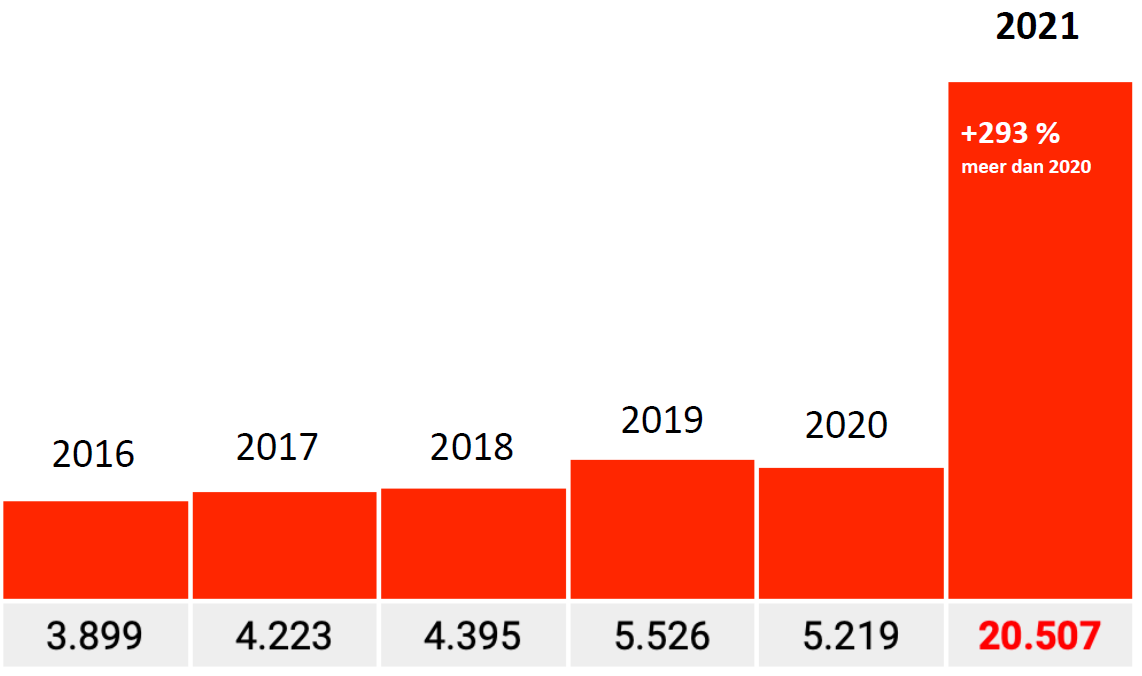
Factor 0,2
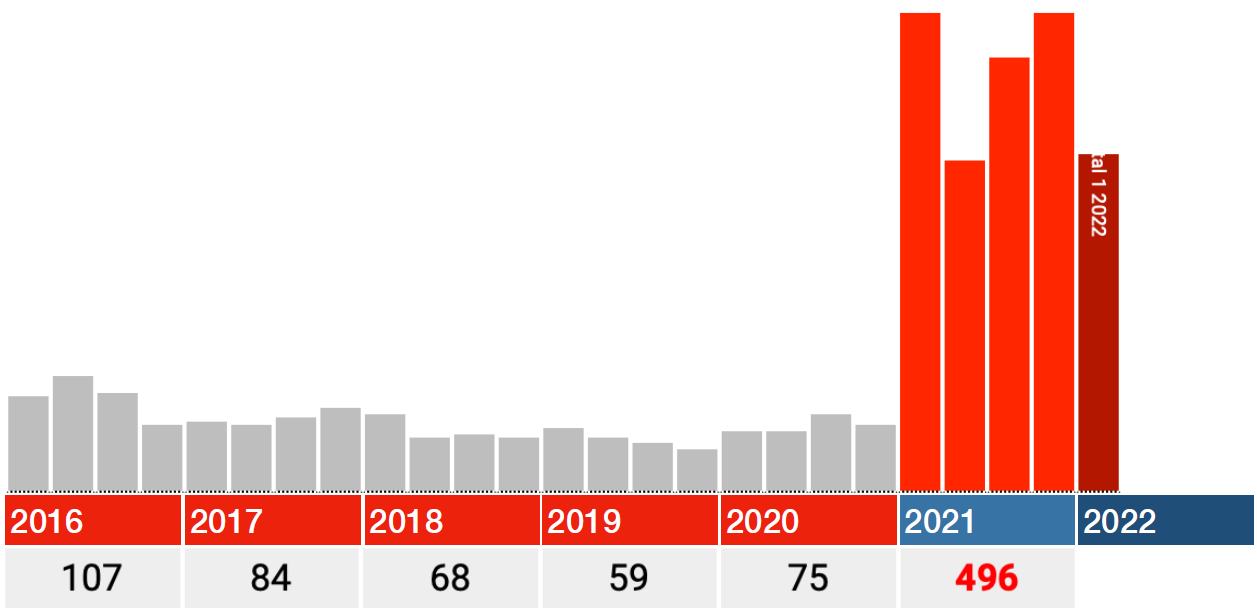
Tot zover de absurde verschillen. Kijken we alleen naar Code I46.1: Overlijden door plotseling hartfalen, dan is het verschil ineens slechts zo’n 20% met 2020. Welke systeemfout of ‘invoerfout’ kan er nu weer zijn gemaakt? Plotseling hartfalen is een echte doodsoorzaak, de andere Codes zijn omstandigheden, misschien is dat anders behandeld? Deze code is ook later toegevoegd.
Zou dit dan de enige grafiek zijn waarin de jaren 2016-2020 wél correct zijn meegenomen? Een stijging van 15-20% oogt in elk geval geloofwaardiger dan een van 1700%. De boodschap wordt er niet minder dringend om: Onderzoek dit! (en stop intussen met dat gevaccineer op niks af).
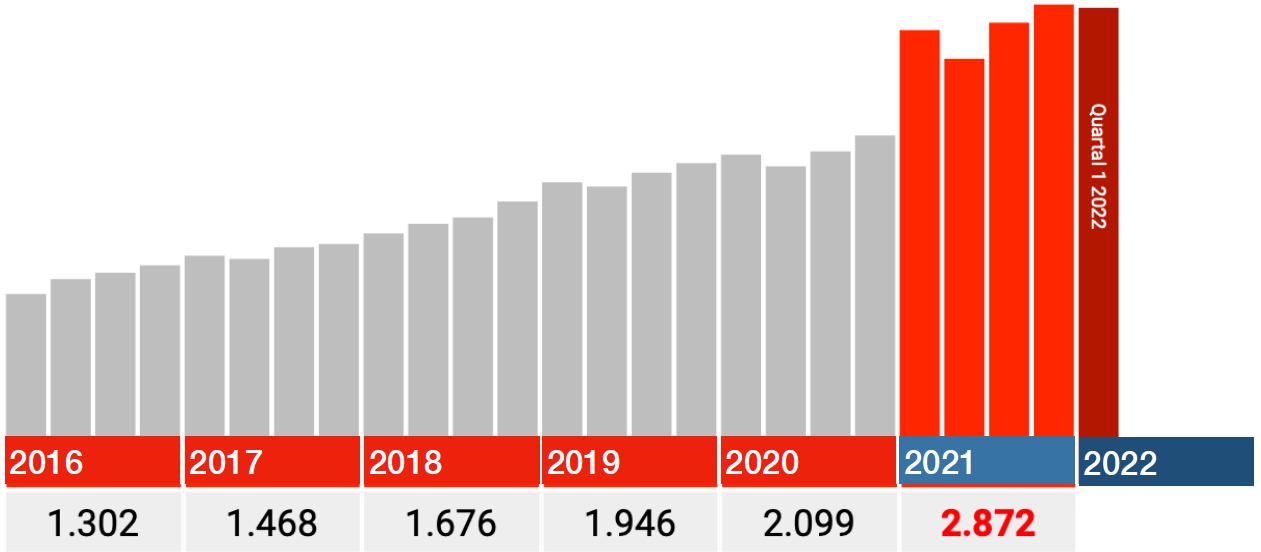
Hoe doen andere I.46 codes het?
Hartstistanden met succesvolle reanimatie (I46.0) lopen in lijn met de normale trend. Data lijken toch echt OK.
Daarnaast is er een categorie “Hartstilstand, niet nader gespecificeerd.” Daarin zien we bijna dezelfde jump als in Overlijden door plotseling hartfalen.

In hoeverre de diverse categorieën doublures zijn of elkaar overlappen weet ik niet, niet elk database-ontwerp is even sluitend.
Deze grafieken zijn gegenereerd op https://corih.de/KBV-Daten/index.php?ohneuberhang=1&uberproz=0&mind=0&icd=I46
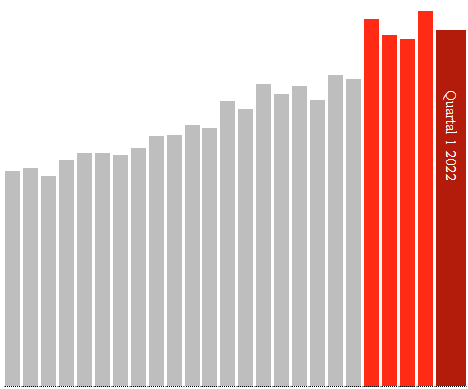
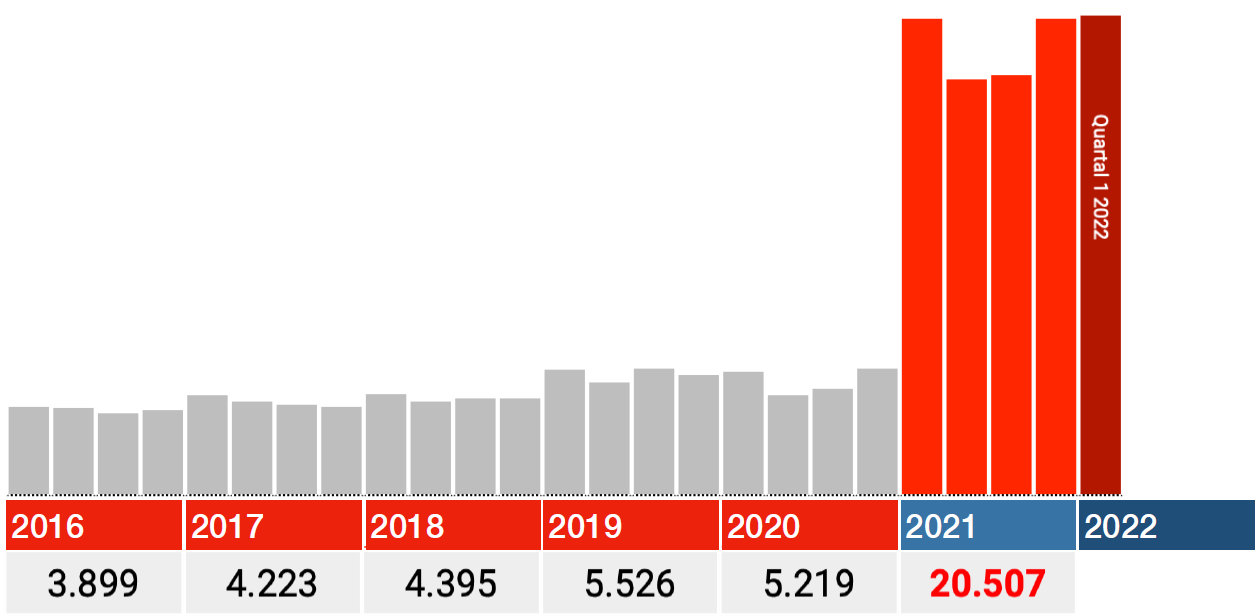
De kwartalen 2021 zijn correct
De data van 2021 lijken ook te kloppen. Kijk in onderstaande grafieken dus alleen naar de rode staven: elke staaf is een kwartaal 2021, de donkerrode is Q1 2022.
In alle categorieën valt de grootste klap meteen in het eerste kwartaal 2021, waarna de aantallen terugzakken in Q2 en vandaar weer stijgen in Q3 en Q4.
Als er ideeën zijn hoe uitgestelde zorg, lockdowns of long covid dit kunnen veroorzaken, hoor ik het graag. Bij vaccinaties kan ik wel iets bedenken: de meest kwetsbaren werden het eerst geprikt. Duitsland begon daarmee eind December 2020.
van andere personen
Hoe ontrolt zich dit nu verder?
Ik ben zeer benieuwd naar het hele verhaal waarmee alle bovenstaande vragen worden beantwoord:
- Hoe komt de vervuiling in de dataset terecht?
- Hoe kan de foutgevoeligheid (mate van vervuiling) per code zo verschillen?
- Hoe kunnen sommige vervuilingen een stabiele/aflopende en andere een oplopende tendens weergeven?
- Als de data niet compleet waren, zijn de data van de I46.1 (plotselinge hartdood) dan wel correct?
Voordat we verder gaan speculeren: eerst maar eens transparantie en open data zodat we er met gericht onafhankelijk onderzoek achter kunnen komen of de vaccinaties hier überhaupt iets mee te maken hebben. Indirect bewijs is er voldoende.
“…de grootste klap meteen in het eerste kwartaal 2021, waarna de aantallen terugzakken in Q2 en vandaar weer stijgen in Q3 en Q4 …. Als er ideeën zijn hoe uitgestelde zorg, lockdowns of long covid dit kunnen veroorzaken, hoor ik het graag.”
Er zijn denk ik veel variabelen. De Alfavariant werd dominant vooral in Q1. Besmettelijkheidsgraad nam snel tot 50% toe en tegelijk, vooral B.1.1.7, bleek een stuk ziekmakender dan de vorige variant.
Daarna kwam Delta als dominant maar tegen die tijd heb je mogelijke invloeden van vaccinaties en lockdown, opgebouwde resistentie enzovoorts. Voor mij is de stijging in Q3 raadselachtiger.
Een ander probleem met Q1’s zijn soms na-effecten van eind Q4 van het jaar ervoor. Mensen worden in een Q1 vaker ziek juist omdat er veel weerstand verdwijnt in Q4, winter, voedsel, thuiszitten enz.
Dat zijn niet echt typische variabelen voor hartfalen of “Minder dan 24 uur na het begin van de symptomen, niet anders gespecificeerd”. Naar eerdere Q1’s kijkend ziet deze er toch best fel uit.
Ik ben bang dat de data vervuiling/foute invoer een plausibele verklaring is.
Je hebt te maken met overheidsinstanties. Ik werk er ook voor en als er ergens slecht met data wordt omgegaan is het bij overheden. Waarom doen ze daar niets aan? Ik geef al 20 jaar oplossingen aan voor simpele registraties die al 20 jaar fout blijven gaan door verkeerde processen en geen! databeheer, ik krijg gelijk en men vindt het prachtig, maar krijg vervolgens geen poot aan de grond en ze doen niets.
Een volgend probleem kan zijn dat door de spontane focus op data en cijfers opeens iedereen serieuzer cijfers is gaan invoeren. Ik heb bijv. voor CBS-statistieken jarenlang cijfers verzonnen omdat het gevraagde nergens in onze bestanden voorkwam. Men eiste een antwoord en kreeg er een, voor de bron is de data waardeloos dus sowhat. En nooit was er een factcheck door het CBS door bijvoorbeeld de cijfers ook elders of anders op te vragen.
En waarom doet de overheid hier nooit wat aan of willen ze er zelfs niets aan doen? Ten eerste heeft het veel nut voor de overheid op niet te beschikken over goede data. (scheelt weer zwarte inkt voor balkjes)Je kan dan namelijk zonder problemen (blijkbaar) gewoon miljoenen blijven verkwisten en niemand doet er wat aan of snapt er iets van. Ten tweede kan je zo het makkelijkst de waarheid verdoezelen. Stel de vaccinatie veroorzaakt slecht 5% meer doden, op zich erg genoeg om er mee te stoppen natuurlijk. Maar als de cijfers zo gaan afwijken als nu dan worden ze ongeloofwaardig en verdwijnen de “echte” 5% door het instorten van de bijv. 17% wanneer het rapport van Tom Lausen onderuit gehaald kan worden voor wat betreft die 17%. Vervolgens als het data-probleem bekend wordt, opgelost kan worden, hoeft hij ook niet meer terug te komen met de “echte” 5%. De geloofwaardigheid is verspeeld.
De overheid houdt zichzelf ook bewust dom. In het land der blinden is eenoog koning. Bijvoorbeeld door een management aan te stellen die niets weet van de inhoud en door de echte inhoudsdeskundigen systematisch weg te promoveren in doodlopende functies. Dit gebeurt sinds 2004 bij IenM structureel, vandaar ook het ene na het andere schandaal of blunders en budgetoverschrijdingen van miljoenen in een jaar. Kijk ook bijv. naar de stikstof aanpak, verkeerd geplaatste sniffers en slechte data en vervolgens een model dat je precies zo kan instellen dat de boeren die jij weg wilt hebben als pieken in de kaart komen te staan. Ook de visserij wordt weer aan de schandpaal gezet door verkeerde data enz. enz. Data is een wapen tegen de bevolking en ze zetten het overal in. En je hoeft er alleen maar stom voor te zijn, de belangrijkste competentie om ambtenaar te zijn naast een universitaire opleiding in kantklossen.
Je bevestigt mijn ergste vermoedens…
Typisch dat er nu beweerd wordt dat deze data niet geschikt zijn om conclusies uit te trekken (in dit geval over trends in doodsoorzaken), terwijl gedurende de gehele pandemie het aantal positieve corona-tests zonder enige kritiek werd gebruikt als ware het een representatieve steekproef van de bevolking. Als de data compleet zijn (en zo niet dan moeten ze simpelweg worden aangevuld) lijkt me dat de kans op bias in dit geval vele malen kleiner is dan in het geval van corona-tests.
Ik kan me trouwens goed voorstellen dat de data niet per ongeluk verkeerd zijn aangeleverd. Door de data de schijn van een onrealistisch sterke stijging te geven wordt het hele verhaal meteen verdacht. Hoewel in Duitsland alleen al de associatie met AfD daarvoor eigenlijk ausreicht.
Kerryn Phelps toparts en politicus in Australië, ernstig en blijvend (?) ziek na 2e Pfizer-vaccinatie. Onthuld dat artsen in haar land worden gecensureerd op straffe van hoge boetes en verlies van registratie.
https://www.smh.com.au/politics/federal/not-anti-vaxxers-dr-kerryn-phelps-says-she-suffered-covid-vaccine-injury-calls-for-more-research-20221220-p5c7ry.html
De ’toparts’ Kerryn Phelps is overigens groot voorstander van lockdowns, vaccinatie- en mondmaskerplicht, ook binnenshuis. Zij riep in september 2022 nog op om alle strenge covidmaatregelen opnieuw in te voeren!
Met zulke hardleerse medici past geen medelijden. Karma is…
Ik heb het artikel uit de Herald vertaald https://virusvaria.nl/oproep-van-australische-hardliner-met-vaccinschade-wij-zijn-geen-anti-vaxxers/
Was de reden om Nederlandse oversterftedata te anonimiseren wellicht om te voorkomen dat het Nederlandse volk er via BSN nummers achterkomt dat slechts een klein deel van Nederlandse politici zich daadwerkelijk heeft laten inspuiten met Spike-eiwit mRNA, net als werd opgemerkt in Japan:
https://twitter.com/riseupandresist/status/1599160471046983680
Daarnaast moet verder worden gekeken dan alleen (over)sterfte; ook toename van ziekte zelf (hart-en vaat, long, neuro, etc.).