Met enige regelmaat zien we prognoses voorbijkomen, die suggereren dat de oversterfte voorbij is. Telkens weer is dat op basis van het verkeerd samenvoegen van cohorten, waaruit vervolgens onjuiste conclusies worden getrokken.
Dit artikel is ook te lezen op de site van Herman Steigstra.
Een voorbeeld, ontleend aan een rekenvoorbeeld dat een criticus gaf. Versimpelde cijfers voor een klein cohort van drie leeftijden met drie verschillende sterftekansen (10%, 20% en 30%). Een hypothetische situatie in 2019 en in 2024:
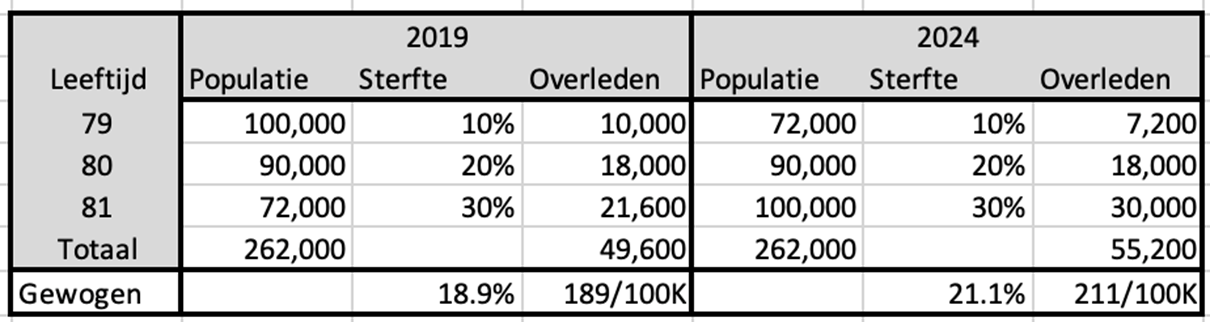
We concentreren ons op de sterfte bij de 80-jarigen. Die sterftekans is 20% en daarbij maakt het niet uit of we in 2019 of in 2024 naar deze sterftekans kijken. In dit voorbeeld nemen we aan dat die kans niet verkleint door betere gezondheid of andere oorzaken. Op basis van de sterftekans rekenen we ook het aantal overlijdens per leeftijd uit in 2019 en 2024.
Vervolgens nemen we aan dat we niet de beschikking hebben over de cijfers van 80 jaar, maar dat ze alleen beschikbaar zijn als samengesteld cohort van 79-81 jaar. We schatten dan de sterftekans voor een 80-jarige als het gemiddelde van de 3 cohorten 79-81 jaar.
We tellen in 2019 dus 262,000 inwoners in dat cohort en totaal 49,600 overlijdens. Als we dat op elkaar delen, zien we een sterftekans van 18,9% en dat is flink minder dan de 20% die we zien bij de 80-jarigen. Alleen door het samenvoegen met de twee aangrenzende leeftijden.
In 2024 verwisselen we de populaties voor 79 en 81 jaar. We zien nu dus meer overlijdens dan in 2019, terwijl het totaal aantal inwoners en de sterftekansen hetzelfde blijven. De gemiddelde sterftekans van het cohort is nu juist hoger geworden. Dus de uitkomst van die sterftekans hangt af van de verdeling van de populaties binnen het cohort.
Hoe het hoort
In 2023 publiceerden we dit artikel: An analysis of excess mortality based on age and sex; the possible role of Covid-19… Hierin beschrijven wij de rekenmethode gebaseerd op trends, die berekend worden op basis van de populaties en overlijdens, maar wel per leeftijd en per geslacht. Inmiddels is dit de basis voor wat we Normsterfte hebben gedoopt.
De berekeningen werden destijds gedaan met een lineair model, waarbij we er dus van uitgaan dat de daling (of wellicht stijging) van de sterftekans evenredig is met het jaar waarvoor we de verwachting berekenen. Voor een beperkte tijdspanne is dat nog wel in orde, immers de sterftekansen wijzigen maar langzaam. In tien jaar zien we een daling van rond de 20%. Maar eens zal de daling nog langzamer moeten gaan of wellicht zelfs tot stilstand moeten komen, we worden immers niet onsterfelijk. Daarom zijn de trendlijnen inmiddels vervangen door een exponentieel model. De verschillen blijken klein te zijn, maar toch…. Als voorbeeld de sterftekans op 50-jarige leeftijd:
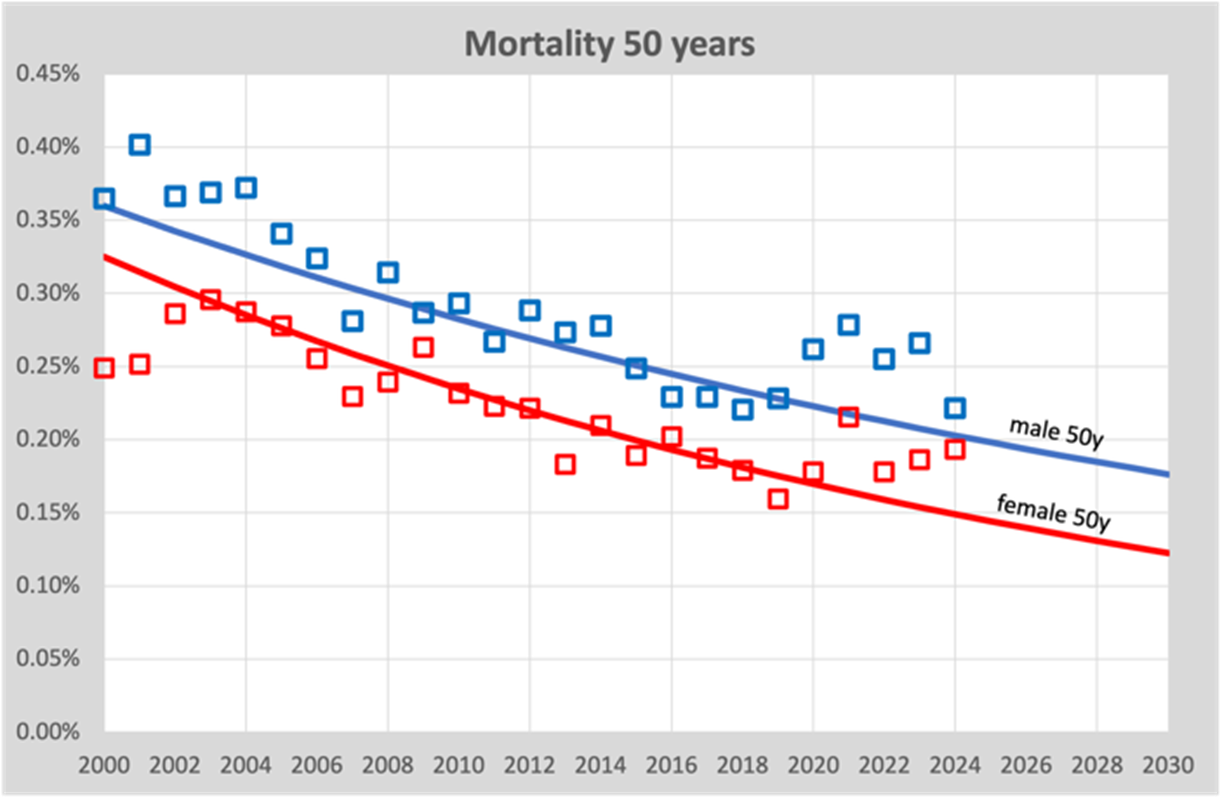
We zien hier dat in de loop van 20 jaar (2000-2019) de sterftekans langzaam afneemt van rond de 0,35% in 2000 naar 0,2% in 2020. We zien ook dat de trendlijn ietsje kromloopt, dat komt door het exponentiële model dat we inmiddels gebruiken. Maar het is minimaal. Belangrijk is dat we de sterftekans langzaam zien afnemen.
We moeten ons dus tegelijk realiseren dat deze grafiek een enkel leeftijdscohort is van alleen 50-jarigen. Vergrijzing van andere cohorten is dus niet van toepassing, dit gaat alleen over de overlijdenskans. Een tegendraadse trend want door vergrijzing stijgen de sterftecijfers van de bevolking als totaal, terwijl theoretisch elk 1-jaars cohort een dalende trend zou kunnen laten zien.
Alle leeftijden samen
We kunnen nu in één grafiek het totaal aantal overlijdens tonen in relatie tot de trendlijn van sterfte van 2010-2019. Dit is deze grafiek:
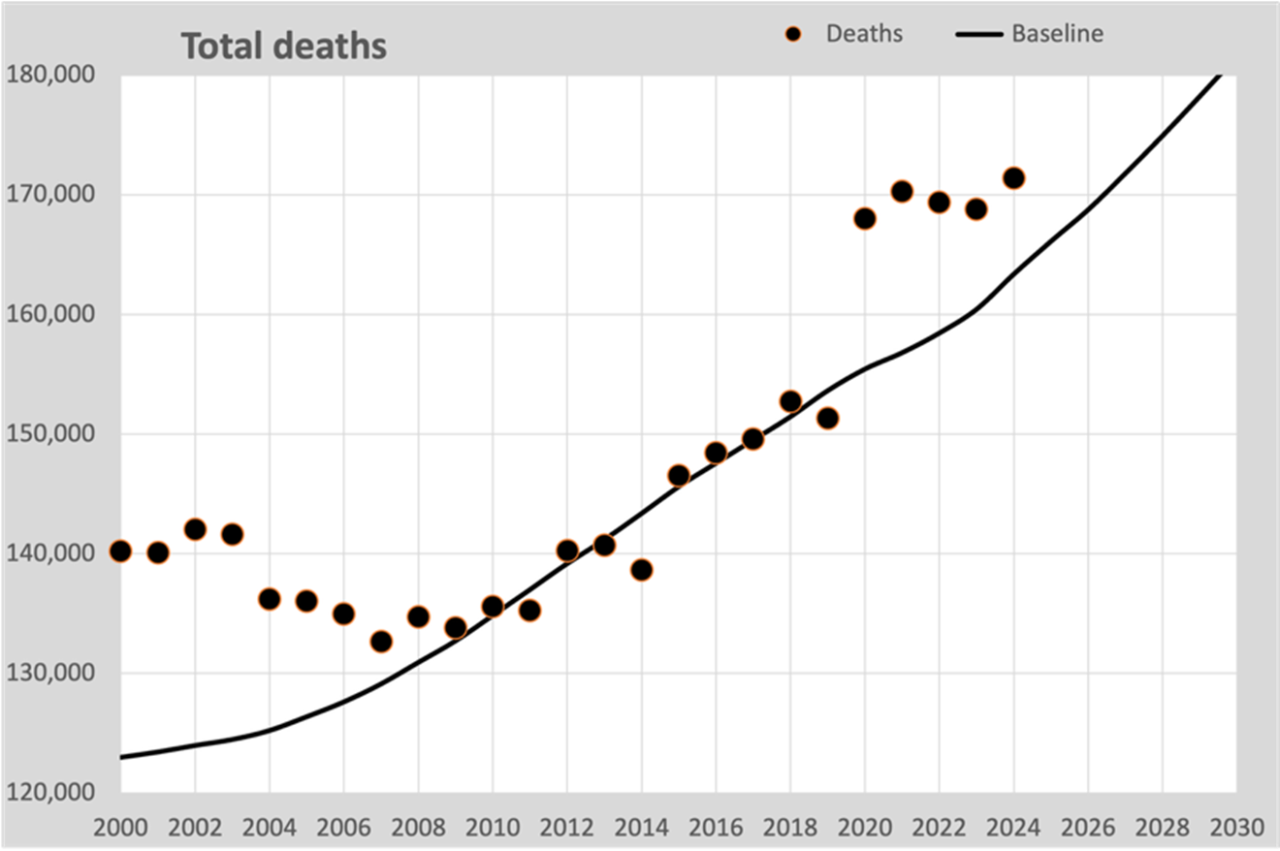
De zwarte lijn is berekend op de te verwachten sterftekansen op basis van alle 1-jarige trends 2010-2019. Die jaarlijkse sterftes passen dus mooi rondom deze lijn.
In 2009 was er een kentering in de afname van de sterftekans. Na een dalende sterftekans, vooral boven de 50 jaar, stabiliseerde de afnemende sterftekans tot ongeveer 2% per jaar. Dat zien we in deze grafiek terug: de dalende sterfte gaat over in een stijging door de vergrijzing.
Nu op basis van jaarcijfers per 100K
In deze stap vereenvoudigen we onze rekenwijze, zoals door velen wordt gedaan. We gaan uit van de totaalcijfers per jaar en reken die om in sterfte per 100.000 inwoners, meestal afgekort tot “per 100K”. Deze grafiek ontstaat dan:

We zien dat de bolletjes ruwweg gelijkliggen in vergelijking tot de vorige grafiek en dat klopt. Voornamelijk is de schaalverdeling anders. Maar ook is de grafiek iets gekanteld, omdat de bevolking langzaam groeide. In 2019 waren er 10.000 meer overlijdens dan in 2000, maar uitgerekend per 100K was het vrijwel gelijk. De bevolkingsgroei en vergrijzing waren de oorzaak. Er waren 1,4 miljoen meer inwoners.
De getrokken lijn is weer dezelfde baseline als uit de vorige grafiek, wederom doorgetrokken tot 2030 met behulp van geschatte populaties na 2025.
Maar dan…
Foute modellen
Veel thuisrekenaars gaan ervan uit dat je door de 100K-punten t/m 2019 een curve kunt fitten, die het verloop na 2020 zal voorspellen.
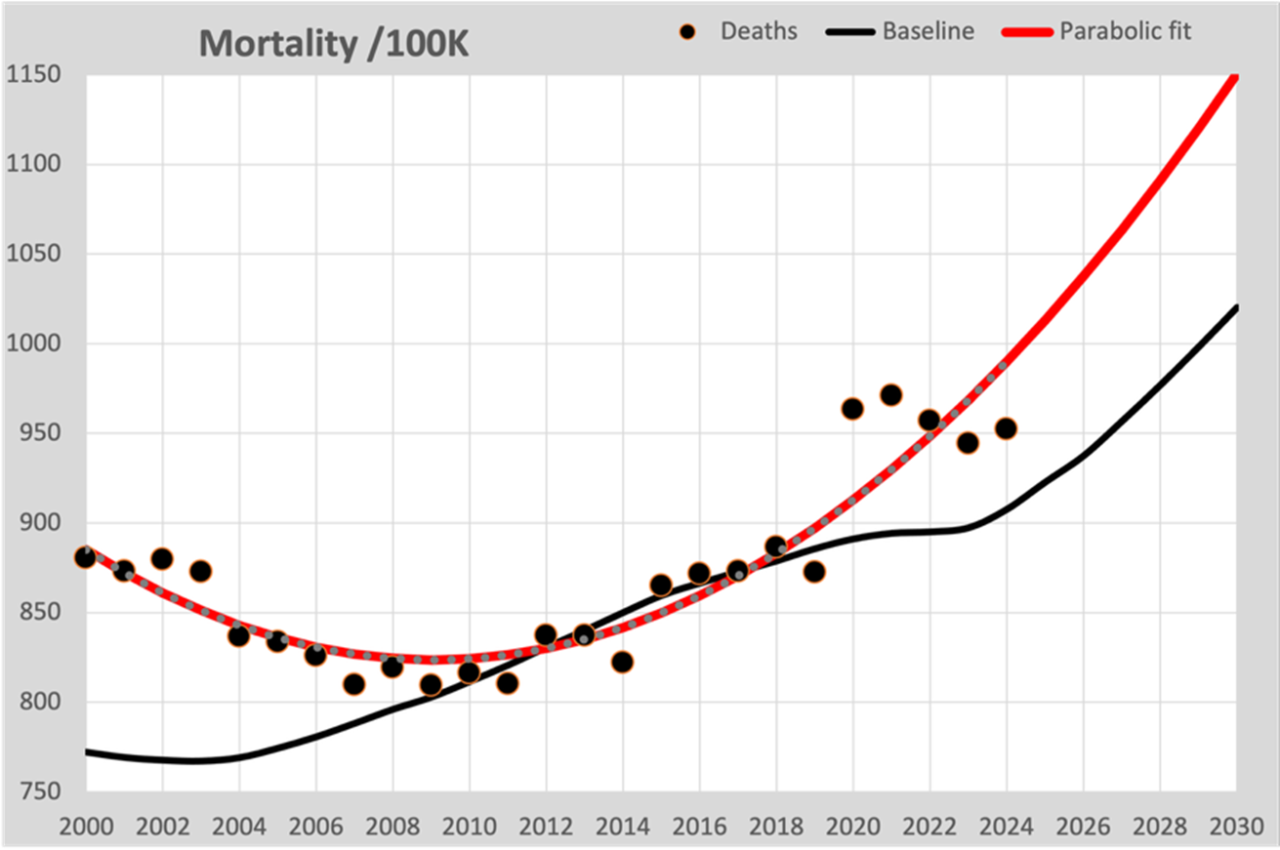
In deze grafiek is nu de parabolische gefitte lijn rood ingetekend, zoals je die in veel grafieken ziet verschijnen. Hier gaan twee zaken fout:
- De gefitte curve (ongeacht het gekozen model) volgt voornamelijk de cijfers die het gevolg zijn van de bevolkingsgroei en niet de verwachte sterftekans. De knik bij 2020 wordt zo gemist.
- De dalende sterfte van 2000 tot 2010 laat hen verleiden te kiezen voor een parabolisch model, dat de cijfers ook vóór 2010 goed beschrijft. De consequentie is dat voor de toekomst dan juist een steeds sterker stijgende sterfte wordt voorspeld.
Het niet meenemen van de bekende cijfers voor bevolkingssamenstelling zorgt ervoor dat de lijn gedwongen wordt om die wijzigende cijfers te fitten. Het is dan ook een foute veronderstelling dat het omrekenen naar overlijdens per 100K van de bevolking dit effect neutraliseert.
Goede modellen
Omdat er nog steeds geen stabiele gezondheidssituatie is, moeten we een “best guess” prognose maken voor cijfers vanaf 2020. De prognose kunnen we grotendeel baseren op de bevolkingssamenstelling zoals het CBS die elk jaar publiceert. De grote onbekende is natuurlijk de te verwachten cijfers voor de sterftekansen. In ons rekenmodel gaan we ervan uit, dat de eigenlijk te verwachten sterfte een voortzetting is van de trend die we tot 2019 zagen. Ook het CBS heeft lang aangegeven dat zij volgens dat principe werken. De totaalcijfers van CBS en ons Normsterfte model kwamen tot 2022 dan ook heel goed met elkaar overeen.
Goede modellen gaan dus uit van individuele sterftekansen voor elke leeftijd en geslacht. Deze sterftekansen vertonen een ontwikkeling door de tijd heen. Het gekozen model bepaalt hoe goed de voortzetting geweest zou zijn als er geen “onverklaarde sterfte” geweest zou zijn. Het is ook nog onduidelijk of wat ons is overkomen sinds 2020 van invloed is op de sterftekans op de lange termijn. Het kan zelfs zo zijn dat er groepen mensen zijn die niet zijn getroffen door wat we nog steeds niet weten. Wellicht dat we daar in de komende jaren meer over leren.
ASMR
De ultieme manier om veranderingen in de bevolkingssamenstelling te compenseren is de ASMR (Age Standardized Mortality Rate). Daarbij worden de sterftecijfers omgerekend naar een standaard bevolking. In ons geval kiezen we voor de bevolkingsopbouw van 2019, de laatste zonder invloed van de “grote onbekende”. Ook de baseline rekenen we op deze manier om naar de cijfers van 2019. Dit is de grafiek die daarbij hoort:
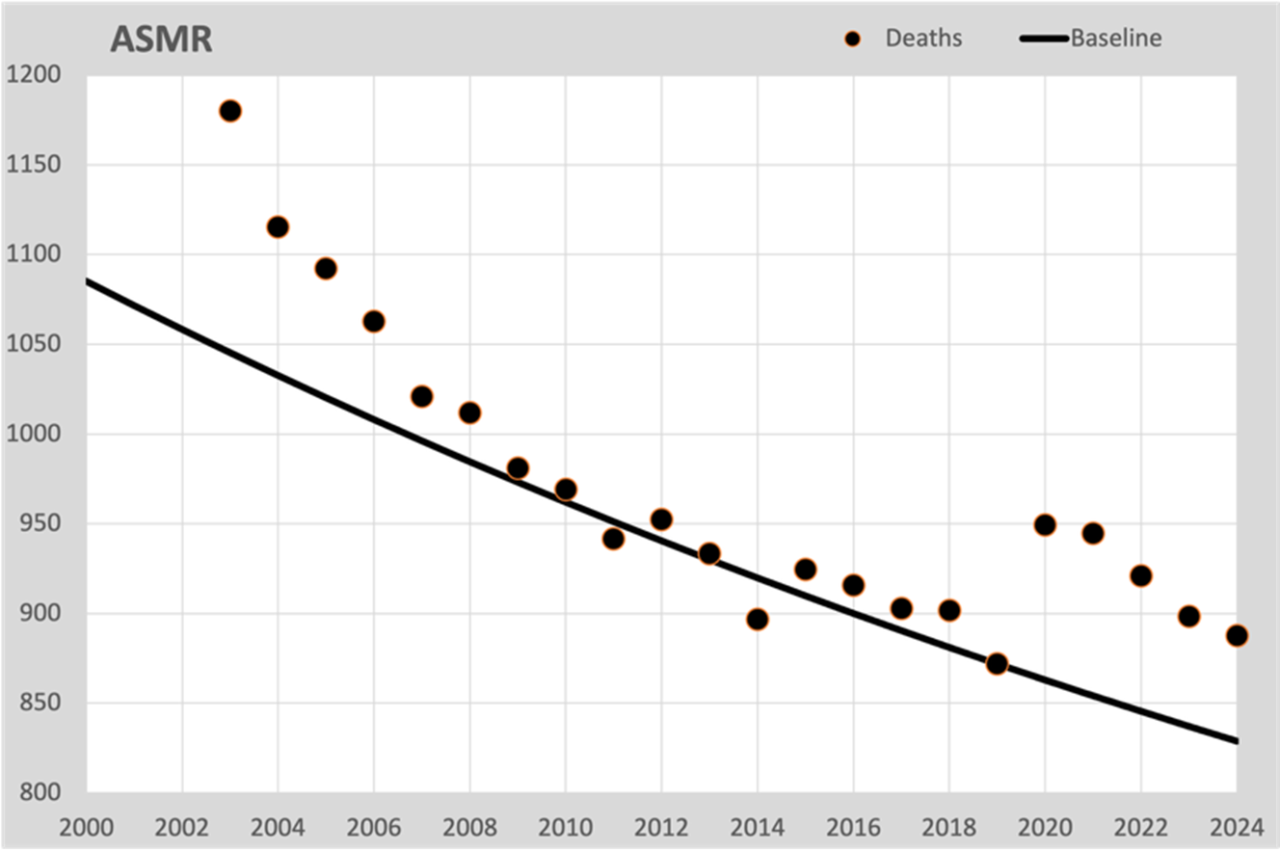
Dit is als het ware de sterftekans als de bevolkingssamenstelling niet zou zijn veranderd, geen vergrijzing. Alhoewel we deze cijfers niet rechtstreeks kunnen vergelijken met de daadwerkelijke sterfte, geeft het wel een goed inzicht in de ontwikkeling van de sterfteverwachting. Net als bij de sterfteverwachting voor 50 jaar in de eerste grafiek ook hier dezelfde daling, berekend voor alle inwoners volgens de ASMR-methode. En het belangrijkste: hier zien we de oversterfte ontstaan vanaf 2020. Ontdaan van alle vergrijzingseffecten. Dus iedereen die vergrijzing noemt als oorzaak van de oversterfte, kan aan deze grafiek zien dat het niets met vergrijzing te maken heeft.
Keuze van historie en model
Een lineaire trendlijn is ongeschikt voor langere periodes waarin zelfs de zachtste kromming een steeds grotere discrepantie zal vertonen tussen verwachting en realiteit. Daarom hebben we nu gekozen voor een exponentieel rekenmodel. Dit veronderstelt dat de sterfte elk jaar met een vast percentage daalt.
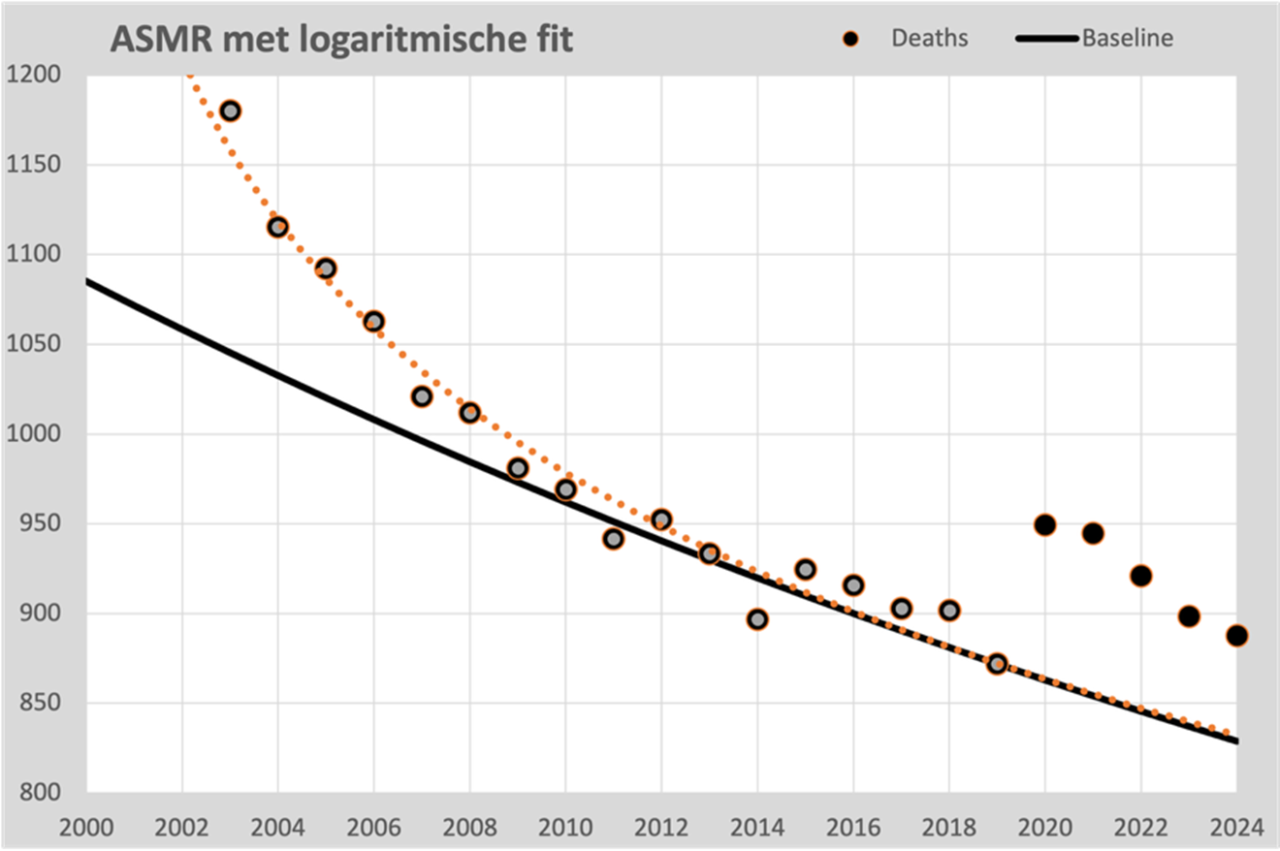
Bij een langere referentieperiode wordt soms gekozen voor een parabool, die tot 2020 een daling en daarna een stijging laat zien. Wil je die curve ook verder in de toekomst kunnen volgen, dan staan er demografische onmogelijkheden in de weg, zoals een aanhoudende versnelling van sterfte, een onwaarschijnlijke ontwikkeling..
Toch laten ook de punten vanaf 2000 een duidelijke regelmaat zien die te formaliseren lijkt. De beste fit vinden we in een logaritmisch verloop, dat vrijwel naadloos aansluit bij de punten 2000 t/m 2019. Het is goed verdedigbaar dat we deze lijn voorlopig kunnen doortrekken; hij leidt niet tot onmogelijke scenario’s. Sterker nog: hij verstevigt de validiteit van de exponentiële 2010-2019 lijn omdat beide lijnen vanaf 2014 nagenoeg gelijklopen.
Conclusies
De prognose voor het te verwachten verloop vanaf 2020 hangt sterk af van de keuze van het rekenmodel en de te kiezen tijdspanne waarmee het model gevoed wordt. We zien deze keuzemogelijkheden:
- Lineair van 2010-2019. Gepubliceerd in Researchgate. Lijkt de te verwachten sterfte goed te beschrijven en geeft een prognose die goed past bij de CBS-cijfers.
- Exponentieel van 2010-2019. Geeft vrijwel dezelfde cijfers, maar is iets realistischer op de langetermijn.
- Parabolisch. Geeft ook voor de jaren 2000-2010 een goede beschrijving, maar voorspelt een sterke stijging vanaf 2020, dat is een keuze.
- Logaritmisch. Een verloop dat niet door een fysische achtergrond wordt onderbouwd, maar wonderbaarlijk gelijkloopt met de cijfers van 2003-2019.
Concluderend: alleen het rekenmodel dat uitgaat van een parabool als model, voorspelt een verloop van de sterfte die vanaf 2020 gedwongen wordt te stijgen. Ondersterfte vanaf 2022 is dan het gevolg. De andere drie modellen voorspellen vanaf 2014 allen vrijwel exact hetzelfde verloop. De eerste twee passen zeer goed bij biologisch verklaarbaar gedrag. De laatste werkt ook zeer goed, maar is meer een optische en cijfermatige fit dan onderbouwd door demografie of biologie.

Goed model, natuurlijk vier!
Dat veronderstelt dat in een normale situatie de sterfte van jaar tot jaar in de meeste leeftijdsgroepen met een bepaald percentage afneemt. Voordeel: sterfte kan nooit onder 0 komen.
Dit is zeker een verbetering t.o.v. het eerder gepubliceerde artikel. Al blijft er helaas, onvermijdelijk, enige speculatie aan ten grondslag liggen. Maar logisch is het zeker. Het is tegelijk echter niet uit te sluiten dat de meest realistische trend ook zonder Corona en zonder mRNA in 2019 een buigpunt had gekend, omdat we al zo verdraaid laag met de sterfte zaten. Maar laten we die discussie even parkeren……
Het 1e grafiekje met zijn fluctuaties maakt mij wel te meer nieuwsgierig naar de cijfers van 2025.
Want zitten de 50-jarige mannen dan weer op of zelfs onder de blauwe trendlijn? Immers in 2024 is hun afwijking van de lijn niet groter dan in 2002- 2006, 2008, 2012 en 2014: de “natuurlijke fluctuaties”.
En hoe zien de vrouwen er in 2025 uit? Back on track, of toch blijvend verhoogd?
Voor nu is m.i. de conclusie:
– vrouwen van 50 = een issue
– mannen van 50 zijn wellicht back on track
Ik ben daarom, nogmaals, heel nieuwsgierig naar de grafieken van 2010 – 2024 waarin je alle fluctuaties kunt zien per jaar en per leeftijd, en niet alleen de waarden van 2019 en 2024 zoals in het vorige artikel. Want deze meer ingezoomde grafiek van alleen de 50-jarigen, maar wel met alle jaren, geeft een mooie illustratie dat er in al die jaren best de nodige fluctuaties waren.
Maar wellicht levert dat toch niet wezenlijk nieuwe informatie/inzichten op…… Misschien komen die grafieken nog een keer? Ik vind het ook prima als ze pas in 2026 komen samen met de 2025 cijfers.
P.S. Leuk dat je mijn extreme (totaal onrealistische) getallen voorbeeldje, geïnspireerd op dat van Herman, gebruikte om het bevolkingsgroei en vergrijzingseffect van 21,1/18.9 = 11,6% op de sterfte van 80-jarigen voor iedereen glashelder te illustreren.
Dank voor je reactie Jan. Je vindt alle cijfers via het Excel blad dat we hebben gepubliceerd in het artikel dat we hiervoor hebben geschreven:
https://steig.nl/2025/04/rekenschema-normsterfte/
Dat is nog het lineaire model.
Cijfers 2025 komen pas rond juni 2026, eerder is CBS niet klaar met tellen.
Dat er in 2020 een “geplande stabilisatie” in onze gezondheid zou zijn, dat is een aanname, die wij niet hebben gedaan. We zien van 2010-2019 elk jaar de sterftekans met ongeveer 1% afnemen, elk jaar. Dat voedt ons niet met het gevoel dat het vanaf 2020 opeens 0% zou zijn “omdat het al zo lang duurt”. De gezondheidszorg is steeds beter in staat om ons leven te rekken, vooral in de leeftijd van 50-60 jaar zien we in de cijfers.
Daarentegen zien wij bij alle jaren 2000-2008 een daling van 2% per jaar. Een knik (snelle schreden bij de ontwikkeling van behandelmethoden??). Daarom loopt ons model vanaf 2010, terwijl het CBS slechts 5 jaar meeneemt voor het berekenen van een trend.
En ja, door dit gegeven gaat een logaritmisch model goed mee met deze knik en gaat er DUS ook van uit dat die afvlakking vanaf 2020 ook zal optreden. Een keuze van je model, net zo goed als dat een parabool veronderstelt dat de oversterfte sinds 2020 daarmee te verklaren is. De keuze van je model gaat bevestigen wat je wilt zien.
En verschillen in de uitkomst van je berekeningen moeten zitten in de onbewuste keuzes die je hebt gemaakt.
Ach, een uit de hand getekende doortrekking van de trendlijn is ook “realistisch” c.q. logisch. Maar dat rekent wat lastiger, dus is die exp() lijn, die exacte punten opleveren, prima. Maar het blijft “schijn-exactheid”. Ik (c.q. Claude) kom dan wel 3% hoger uit dan jij. Dus wat minder oversterfte.
Ook dan geven de dames van 50 nog een duidelijke oversterfte voor 2024; en de heren zitten dan binnen de bandbreedte in 2024. Dus zijn de cijfers van 2025 cruciaal om te zien waar het heen gaat met de heren (en ook met de dames natuurlijk….).
Ik had die Xcel gemist; dank; ik ga kijken of ik die ontbrekende grafiekjes zelf kan maken. Al heb ik nu heel weinig tijd….
In het excel staan de trendlijnen voor alle leeftijden. Dus alle grafieken die je in je hoofd hebt. En stel gerust je eigen varianten samen door cohorten te combineren.
Thanx, ik ga er naar kijken.
En. Ik ga ze natuurlijk juist niet combineren…..
Dat hangt af van de vraagstelling. Als je bv wilt weten hoeveel sterfte je verwacht boven de 65 jaar, dan moet je vermenigvuldigen en optellen.
Nee, dat interesseert mij niet zo veel.
Ik ben alleen benieuwd naar oversterfte per jaargang en hoe de trend per jaargang er dan uitziet. Dus ca. 80 (of ca. 160 m/v) grafiekjes met een stuk of 20 jaren er in (x-as) en overleden/100.000 (y-as). Misschien kan ik ChatGPT zo gek krijgen om al die grafiekjes ff te genereren……
Nog even 2 details:
1. Ik snap niet waarom logaritmisch wel de “realiteit” volgt en exponentieel totaal niet. M.i. kun je bij exponentieel de 3 parameters a · e^(bx) + c ook zo kiezen dat hij in een gladde curve praktisch overeenkomt met een logaritmische curve in de reeks 2000 – 2019. In ieder geval veel beter dan je illustratie suggereert!
2. Je schrijft ” Logaritmisch van 2000-2019. Een verloop dat niet door een fysische achtergrond wordt onderbouwd, maar wonderbaarlijk gelijkloopt met de cijfers van 2003-2019″ Volgens mij hebben heel veel natuurlijke processen een logaritmisch (verminderend met asymptoot, bijv. verzadigingseffecten, afnemende meeropbrengsten, learning curves, aanpassing aan nieuwe behandelingen, de makkelijkste verbeteringen worden eerst bereikt, daarna wordt verdere verbetering steeds moeilijker) en/of exponentieel (half waarde, bijv. elke verbetering in gezondheidszorg geeft een constant percentage verbetering) verloop. Dus het is helemaal niet zo wonderbaarlijk….
Dubbelcheck:
Claude komt met exp() een stuk hoger uit, nl. 855/100.000 ipv bij jou circa 830/100.000. Dat scheelt ca. 3% en is voor de definitie van oversterfte best heel veel. Of had jij een heel andere exp() functie?
Rara?
De log() functie (heeft slechts 2 parameters) past niet makkelijk door 3 punten, maar een benaderde log() komt ongeveer op jouw 830/100.000 uit.
P.S. Claude vindt veel gemakkelijker een goed passende exp dan een log functie. Jij beweert het omgekeerde.
Rara?
Exponentiële functie
y = 516.204 × e^(-0.133482x) + 834.132
Voorspelling 2024
855.1
Logaritmische functie
y = 1360.342 + -166.417 × ln(x)
Voorspelling 2024
831.5
Verificatie: Passen de curves door de 3 ijkpunten?
Jaar Werkelijk Exp voorspeld Exp fout Log voorspeld Log fout
2003 1180 1180 0 1177.51 -2.49
2010 970 970 0 977.15 +7.15
2019 875 875 0 870.34 -4.66
Daar waren Herman en ik het ook niet helemaal over eens. Het blijft een keuze voor een beschrijvende benadering. De demografische benadering blijft toch de best verdedigbare voorspeller.
Zelf vertrouw ik op Excel voor het tekenen van trendlijnen. Ik weet dus niet precies welke ‘ijkpunten’ je bedoelt, ook niet waarom juist die jaren ijkpunten zouden moeten zijn. Ik voer de hele reeks aan Excel, ik selecteer geen jaartallen waarvan ik denk dat die belangrijker zijn (of betere steunpilaren voor een lijn) dan andere. Dan is het eind weer zoek.
De segmentkeuze is zelfs al bepalend. Als je 2000 als startpunt neemt in plaats van 2003 (of 2002, dat gaat ook nog), dan klopt het al niet meer. De periode vóór 2000 is weer anders. Het blijft een soort cherrypicking: welke oogt het best en zou iets voorspellends kunnen weergeven? Welke kristallen bol blijkt straks gelijk te hebben gehad?
Voor de prognose maakt de keuze tussen die twee (en zelfs nog wel lineair) op dit moment niet zo heel veel uit voor de tienduizenden onverklaarde doden.
Misschien rekent Claude net iets anders dan Excel. Ik heb er eerder eens met ChatGPT over gesteggeld, die zegt: De log-trend in Excel heeft de vorm: 𝑦 = 𝑎 ln(𝑥) + 𝑏
Ik heb het voor kennisgeving aangenomen.
Overigens hebben we het niet over een ‘buiging’ in 2021 maar over een onverhoedse plateauverhoging, een trendbreuk uit het niets, die onmiddellijk weer afplat en langzaam terugzakt, hopelijk blijvend.
Er is gelukkig een langzaam dalende trend te ontwaren, al eindigde toch 2024-2025 hoger dan 2023-2024. Ik vind de focus op 2024 niet zo bijzonder interessant. Überhaupt zou het veel beter zijn om naar de seizoensjaren te kijken, maar ja, dan loop je weer zo naast het spoor. Je zou hebben gehoopt dat het na 2021-2022 afgelopen was geweest – of eigenlijk: direct na het vaccineren. Dat was immers beloofd. Het is afwachten wat 2025-2026 gaat doen, met name deze winter.
Wat bedoel je met demografische vs. beschrijvende benadering?
Voor een vergelijking met 3 onbekenden heb je 3 ijkpunten nodig. Ik heb de uitersten uit de grafiek genomen en een ongeveer in het midden, dus 2003, 2010 en 2019. Je zou bij die keuze geen uitbijters moeten nemen, maar punten die op voorhand zo veel mogelijk op het midden van de lijn liggen. En dat was 2010. Vandaar.
Ik ben het niet me je eens dat lineair hetzelfde oplevert. Dat scheelt echt behoorlijk veel zoals je uit mijn vorige post kunt opmaken. Er is dus een betere fit met een exp() functie dan die Xcel voor je berekent: die van Claude. Maar je hebt gelijk: het blijft extrapolatie naar de toekomst, en dus koffiedik kijken.
Zeker is er in 2020 e.v. een flinke afwijking van de trend tot dan. Ik bedoelde dat er in 2019 er een buigpunt zou kunnen zijn (net als omstreeks 2010) vanaf waar de levensverwachting sowieso minder snel zou stijgen. Nogmaals, dat is en blijft speculatie. Niemand heeft daar De Waarheid in pacht. En door de verstoring van Corona (en de “grote onbekende”) zullen we helaas nooit weten hoe het zonder die verstoringen zou zijn gelopen…..
Ik vond de seizoenen van Bonne ook zeer verhelderend. Weinig tegen in te brengen….
Wij trekken geen lijn door 3 punten, maar 200 lijnen door 20000 punten en daarvan per jaar een product van 200 lijnen met 20000 bevolkingsaantallen.
Demografisch: Voorspelbare bevolkingsopbouw wordt meegenomen
Beschrijvend: Een formule die beschrijft hoe een patroon (meestal een lijn) van uitkomsten ongeveer loopt.
En als het verloop van de curve vrijwel volledig wordt bepaald demografie, hoef je het niet meer te beschrijven, want deze cijfers zijn al bekend….. 🙂
Als een periodeverloop met een formule is te beschrijven, is dat een serieuze voorspelkandidaat. Als de voorspellingen niet kloppen met de demografie was het toch aardig dat het zo lang goed ging 🙂
Mijn punt is dat de bevolkingssamenstelling exact bekend is. Je gaat geen parabool “bedenken” om dat verloop te beschrijven. Die moet je als een gegeven in je model meenemen. Wat overblijft is vervolgens een model dat alleen je ontwikkeling in gezondheid weergeeft.
Als de prognose toch goed overeen zou komen, is dat nog geen bewijs dat het model correct is.
Mooi artikel met prima grafieken die ik ook zal gebruiken. Naar mijn idee om vooral door de oogharen te kunnen kijken en niet verder proberen er nog speculatieve inzichten aan te ontlenen. Dit is nuttig om de sterftesprong te kunnen scheiden van een vergrijzing die immers geen turboverrijzing kan zijn.
Zoals bekend streven we bij de Biomedische Rekenkamer nog steeds naar meer transparantie van cijfers. Bij RIVM. Bij het CBS. Tot aan ruwe data voor ingevulde doodsoorzaken aan toe, maar het CBS verklaarde zich niet ontvankelijk vanwege de Wet op de CBS. Daar moet dan, gezien deze uitleg van de wet, een politieke oplossing voor komen in de vorm van een wetswijziging. Als althans behoorlijk bestuur het oogmerk is. En wat VWS/RIVM betreft, we wachten nog steeds op het Hoger Beroep in de Deltavax-zaak! Raad van State, kom door met die planning, zou ik zeggen.
En verder werken we met een focus vooral op de pathologie. Ieder inzicht zal geïntegreerd moeten zijn met causale medische observaties. Daar is eigenlijk al heel veel van bekend, ondanks dat onderzoek actief wordt onderdrukt en ontmoedigd. En binnenkort volgt meer over hoezeer er zand in de gezondheidsmotor is gestrooid en hoe dat detecteerbaar is. Met ernstige gevolgen voor mortaliteit, maar ook voor morbiditeit. Stay tuned!
Hallo Cyril, dank je!
De goede werken van de BMRK volg ik op de voet. Ik heb er recentelijk weer aandacht aan besteed, zoals je hier misschien hebt gezien.
Causale medische observaties zijn er zeker al. Alles hangt af van hoe de media daarmee omgaan. Tot nog toe is er weinig interesse voor. De redenen liggen voor de hand.
Datatransparantie is cruciaal; wat mij betreft zelfs prioriteit 1 want causale observaties worden zonder cijfermatige impact makkelijk als anekdotisch, niet significant of zelfs als desinformatie weggezet. Dat zien we nu. Ik ben heel benieuwd of de kamerleden het met een wetswijziging eens gaan zijn – als zo’n voorstel er al komt. Duimen maar en doorgaan!
Beste Cyril,
Dankjewel voor je positieve commentaar. Als we jullie nuttige activiteiten kunnen steunen, laat maar weten!
Ben ook bezig met een artikel over “effectieve vaccinatiegraad”. Daarmee kun je op basis van de wel bekende cijfers een goede schatting van de effectiviteit van het vaccin berekenen. Maar door tijdgebrek zit er niet veel vooruitgang in het schrijven.
Vooral zeer nuttig in de eerste maanden van vaccinatie, als de ongevaccineerde groep nog veel groter is dan de ongevaccineerde. Nuttig om even in het achterhoofd te houden!
Groet, Herman
Wordt virusvaria staatsgevaarlijk?
Ik krijg sindskort automatisch een privacy waarschuwing bij zoeken naar site!
Inderdaad, het is gevaarlijk om deze site te bezoeken.
Je zou zomaar kunnen gaan twijfelen aan het voorgeschreven narratief.
Tijd voor een naamswijziging? ‘Excelent’ komt in mij op. Excel, ent (meerdere betekenissen), inenten, excellent… wellicht heb ik teveel fantasie maar helaas heb ik ook ervaringen met vreemde waarschuwingen.